| ■1 回答集計方法の概要 このサイトは民間プロバイダの提供するwebサーバを利用して個人が作成しているものなので,既設のサーバプログラム以外は使用していない.作者はサーバログも入手していない. 次の手順で回答を集計している. (1) 各頁ではブラウザの機能として,「採点する」「ヒントを出す」「次のページに進む」などの操作ボタンが押された時間をメモリ上に記録する. (2) 回答集計に同意した読者の記録は,プロバイダ提供のメール送信フォームから作者に届く. (3) メールをエクセルマクロで読んで分析する. ※ 回答者属性(中学何年生か)を含むアンケート全体を表わすときは「回答」,各問題ごとに正しいか間違っているかが決まる答案だけを表わすときは「解答」と表記している. |
(参考) コンピュータの教育利用が進んできたとはいえ,学習者の気持ちはなかなか分からない. 先進的な研究の中には,学習者の血液成分やペンタブレットの圧力の変化から気持ちの変化を測定したり,教室内の学生の視線の動きから集中度を測定したりするものもある. 当サイトの場合,特別な入力装置ががある訳でもなく,自分の生徒がいる訳でもないので,「教材を無料提供する代わりに,読者からデータを送信してもらう」という方法をとる. この分析では,「学習者の気持ち」といっても個別指導のために各自の気持ちの微妙な違いに焦点を当てるのではなく,回答者全体の傾向を捉えようとしている. 一見バラバラに参加している登山者でも全体の傾向として,「この看板では分かりにくい」「この岩場は登りにくいのではしごを付けよう」「この迷い道には注意する必要がある」など全体の傾向を推定すると登山案内がしやすい・・この文脈で登山を学習に置き換えてもらうと案内者が欲しいデータが分かる. |
| ■2 集計期間中に読まれた件数 統計的な推測の精度は,母集団に対する標本の比率には関係なく,標本の大きさ(データの個数)に関係する. 各分析の表中に「集計期間中に読まれた件数」(および%)も表示しているが,統計的には意味がなく,単なる参考となる. ただ,回答者から見れば,どれくらいの規模の集計の中に自分が参加していたのかという目安が得られると納得しやすいと考えられるので,参考として記録している. この件数は,無料アクセス解析を利用して各頁ごとに把握したものを利用している.(画面左下に小さな長方形が灰色で表示されているときにカウントしている) |
例 選挙開票速報において,開票率1%でも「当選確実」となることがある.標本がランダムに選ばれていれば数十件のデータだけで全体の予想はできる. 標本の大きさ(データの個数)が数百,数千となれば,推測の精度が上がる(±数十%の誤差→±1%の誤差など)が,判断が逆転するようなことはあまりない. 標本がランダムに選ばれているかどうかが重要で,偏った層だけから標本を選ぶと全体予測を間違う.そこで,アンケート調査では,男女別,年齢別などの回答者属性に偏りがないように注意する必要があるが,当サイトの方法では,回答者が選んだ回答者属性を信用する以外に方法はない. |
| ■3 最初の問題に着手するまでの時間 ■2で述べたように,各頁には操作ボタン以外の特別なものはなく,一覧形式で提示している教材では,読者の視線がどの文章を見ているのかは直接には分からない.このため,ある解説が分かりやすいかどうか,その解説はその場所に必要かどうかなどを読者の行動から判断するために,「解説が読まれた時間」「操作方法が納得できるまでにかかった時間」=「最初の問題に着手するまでの時間」が手掛かりとなる. 右図において赤丸で示した点が時間を測定できる箇所とする. 中学数学の用語で言えば,右の直線の傾きが「1題当たりの所要時間」になる.この場合において,初めの解説が読まれた時間は右図○の時間を推定すれば求まる.(切片を求める) 切片を推定するために,第1問完了時間から「1題当たり所要時間」(平均値)を引く方法が考えられるが,右図2のように実際に使う問題配列では,番号が進むほど難しくなるのが普通で,その場合第1問完了時間から1題当たり「平均」所要時間を引くと負の値となり,うまく求まらない.(朱色で示したもの) そこで,1題当たり所要時間の平均値を使うのをやめ,単純に第2問完了時間との差を引いて右図○の時間を求めることにした.(2次,3次,・・曲線による近似でもよい.) このようにして,第1問と第2問が問題形式,問題文の長さ,難易度などでほぼ同質のものであれば,後者の方法により,そうでないときは前者の方法によることとした. 各頁において「3題以上解答すれば送信可能」としたのは,一方においては空データの繰り返し送信を防ぐためでもあるが,他方においては第1問〜第3問の解答時間が凸凹になっていないかどうかを確かめるためでもある. |
図1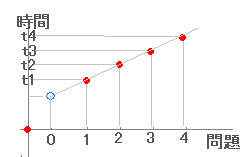 2番目の点=第1問を採点したとき,3番目の点=第2問を採点したとき,・・・ 図2 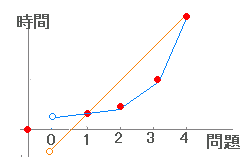 |
| ■4 誤答分析 教育心理には「誤答分析」という分野があって,学習者個人ごとのつまづき克服の資料を提供するとともに,教員側には指導計画を立てる参考資料を与えるものとされている. この頁では,全体の傾向を把握して,教材改善を図る側面で利用しており,誤答の多い問題を見つけてその原因を探る. |
誤答原因を探るために相関係数をしばしば参照するが,相関係数だけで結論を出すのは無理で,他の方法で確認するのがよいと思われる. 特に小問数が少ない頁では,相関係数から一定の傾向が見られても問題の組合わせに左右される可能性があるので,他の頁の結果と合わせて確かめる必要があると考える.(下記■7参照) |
| ■5 標本と母集団の関係 回答集計を「何人かの生徒でこんなテストをしました.その結果はこうでした.」という形で読めば,それが他の人に何の関係があるのか分からないが,標本が偏っていない限り標本の性質はその母集団の傾向を忠実に再現する.したがって,ある集団が成績上位群や成績下位群のような偏ったものでない限り,集団を変えても時期を変えても結果は家の鍵の「鍵型」のように,細かな構造まで一致する.一人ずつは違うのであるが,集団にすれば傾向が一定となる. 上記の話は,統計の教科書を読めばあたりまえのことであるが,学力とか心理のような抽象的で捉えにくい分野でDNAやスペクトルのような精度で同じ形が再現されるのは正直言って驚きである. 一見,特定の村の特定の学級の話をしているように見えるが,全国共通の傾向を調べるのを目標としている. |
* 遠い目標 都道府県や学校,さらには授業担当者が変れば成績は変るが,それぞれの集団の成績は学習指導要領や教科書で想定されている教材の配列や分量をも反映している. そこで全国平均の傾向を求めると,都道府県・学校・授業担当者の差異が取り除かれて,「その項目自体の難しさ」「教材の配列や分量の影響」が浮かび上がるのではないか. さらに各項目の前提となる下位目標の多変量解析がうまく働けば,調査していない項目の正答率も予測できるのではないか. ・・・ ここら辺の遠い目標を意識しながら,回答集計と分析を行いたい. |
| ■6 成績アップについて 分析の中で各頁の演習を行ったときの「成績アップ」の見込みについて述べている箇所があるが,その意味は次の通り. 演習問題を行ったときに,各問題の第1回目の解答が誤答で,再試行(再々試行,再々再試行・・・も含む)の結果正答に変化したとき,その学習者にとっては「できなかった問題」が「できる問題」に変化したことになる.そこで,頁全体の正答率が第1回目の答案から2回目以降に改善されているときに,その正答率の上がった分を「成績アップ」の見込みと表現している. |
※ 学校で行われる試験においても,やり直せば結果は大きく変ることがある.学力は,身長や体重のように外形的に安定した量とは異なり,測り方,その日の体調などでかなり変動するが人ごとに一定のゾーンの中に入っているという意味では血圧によく似ている. 「本当の学力」とは「真の学力」とは・・・というように要求水準を高めていくと,決められないという結論しか出ないが, この分析ではそのような高尚な内容を求めず,測定可能な統計データを用いて誤答が正答に変化したときに,これを学習の結果として「できるようになった」と「見なして」いる. もっとよい用語があるかもしれないが,教育関係者だけでなく中学生程度の読者も読む可能性があり,単純にイメージしやすい用語として「成績アップ」とした. |
| ■7 各頁の分析結果の見方について 統計的な差異の有無は,与えられたデータに依存する. 例えば10問の問題に対して50人〜100人の回答があるとき,各々の問題の正答率・所要時間などは回答数が増えると統計的に安定し,一定の値に収束する. しかし,誤答原因を調べるために問題間の差異を調べているときには,問題数はわずか10問のまま固定されているので,回答数が増えることは個々の正答率・誤答率の精度をよくするのに役立つだけで問題の組合わせに付着している限界を取り除くことはできない. 例えば,中学校2年生の1次関数のグラフについて,誤答原因が「傾きが負であること」に依存するか「傾きが分数であること」に依存するかは,問題の組合わせによって変る. |
一般に,誤答の原因がn種類考えられるときに,それらの有無が誤答に及ぼす影響を調べるには,最低でも2n個の問題で比較しなければならないが,「問題数を多くし過ぎると回答が集まらない」. そこで,わずかな問題数から誤答傾向を判断しているときは,その頁だけで完結した結論を述べているのでなく,暫定的な仮説を投げかけておいて他の頁の分析と共通の傾向が見られるかどうか待つ形になる. 個々の曲面で見られる |
■各分析に用いる用語の意味(作者なりの解釈)
| ■正答率(通過率)・誤答率 何らかのテストを行ったとき, (正答率)=(正答者数)÷(回答者総数)
とすべきところ,この(回答者総数)を慎重に選ばなければならない.(ア)何らかの事情で問題を見ることが出来なかった者 (イ)問題を見ることは出来たが回答しなかった者 は区別しなければならない.正答率の定義においては,問題を見ることができた者を分母にすべきものとされている. 「eテスティング」(培風館/植野真臣・永岡慶三著) |
(当サイトでの実際の運用) 当サイトの集計においては,各問題の採点結果はA:「正答」,B:「誤答後訂正して正答」,C:「誤答のまま終了」,D:「無答」の4種類に分けられる. A→正答, B,C→誤答 は明らかであるが,D:「無答」の答案を分母に参入するかどうかを考えてみる. 左の定義において(ア)は「回答する意志はあったが回答することができなかったもの(障害未遂)」を,(イ)は「回答しようと思えば回答できたが,本人の意志で回答しなかったもの(中止未遂)」を表わしていると解される. 当サイトの問題では, I)一度に全部見える形式になっていて,見ようと思えば下端の問題も見ることが出来た場合, II)頁送り方式になっていて,途中放棄すれば,後半の問題が見えなかった場合 の2つの場合があるが,いずれも「見た」かどうかではなく「見ようとすれば見ることができ,回答することができた」と考えられるので,本来すべて「回答者」に含めて差し支えないと考える.もしネットワークやパソコンのトラブルで見えなかった場合は,送信できていないはずである. 《理論上はここまで》 ところが,教員の指導も何もないWeb教材では脱落・途中放棄がしばしば発生し,問題数が多い頁では後半の問題の多くは無答答案となる.このとき無答答案を「誤答」に分類すると,簡単な問題でも正答率の低い「難しい問題」に分類されてしまい,判断を間違うもととなる. 当サイトでは問題の難易度などが分かれば十分であるから,無答が少なければ無答を誤答に含め,無答が多くて分析が難しいときは無答を回答総数に含めずに集計する.(柔軟に対応) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ■ 弁別指数(UL指数,U−L指数)・・・古典的テスト理論においてその項目の識別力(回答者の学力の高低を見分ける力)を示す指標 弁別指数=(上位群の正解率)-(下位群の正解率)
*1で定義される. 上位群,下位群としては,通常上位から27%,下位から27%を用いる. その問題で上位群と下位群とにどれだけ差が出るかを表わすもの *2 目安として, 0.4以上となれば弁別が非常によい問題, 0.3以上0.39以下となれば弁別がかなりよい問題, ・・・ 0.2以下となれば不適切な問題と考える. *3 この27%という数値は,最初の考案者が用いたものでこの数値でなければならないという理論的根拠が示されている訳ではないが,多くの文献でこの27%が用いられている. ●[文献] 「項目反応理論入門」(イデア出版局/高橋正規著p.93,p.238) ●[Web上の記事] http://www.apec.aichi-c.ed.jp/shoko/kyouka/gakumath-h20/4.htm http://incet.naruto-u.ac.jp/file/kiyou3/saitou.pdf 表1
|
[続き]
例1・・・表1からUL指数を求めるには (1) 受検者数が18人であるから,その27%は4.9人≒5人 (2) 合計得点を求めて,上位5人,下位5人を選んでその正答率を求める. (表1は合計得点の少ない者から順に並べ替えてある.) (3) 次のような結果となり,第2問,第3問は識別力が低く,第1問,第4問〜第6問は識別力が高いといえる.
(当サイトでの実際の運用) 当サイトの問題は,簡単なので正答率が非常に高いことが多い.しかしまた,数学を苦手とする読者も多いため,どんなにやさしい問題でも誤答・無答はある.そこで,機械的に上位27%,下位27%をとると,正答率100%と正答率0%に近いものに分かれ,問題ごとの差異は分からない.そこで,上下に折半して上位50%を上位群,下位50%を下位群とすることが多い. さらに上位群,中位群,下位群に分けると一層詳しく分かることがある. 次のグラフ(ロジスティック曲線)は,「むずかしい問題」と「やさしい問題」における学力と正答率のモデルで,やさしい問題においては中位群の正答率は上位群の正答率に近く,むずかしい問題においては中位群の正答率は下位群の正答率に近くなると考えられる. したがって,全体の正答率が高い(=やさしい)問題において中位群が上位群に近く,全体の正答率が低い(=むずかしい)問題において中位群が下位群に近いときは,自然な分布になっていると判断できる. 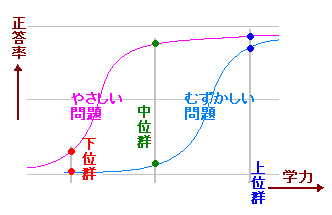 問題ごとの識別力を示す指標としてはI-T相関,I-R相関があり,これらを併用する.(下記) なお,異質な解答状況となる生徒や問題を見分ける方法として,古くからSP曲線を利用する方法があり,S注意係数,P注意係数がよく用いられている.当サイトでは問題の分析のみを行い生徒の分析は行わなわず,問題の分析はI-R相関やU-Lグラフなどで代用できるので,P注意係数は用いていない. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ■ 点双列相関係数・・・古典的テスト理論においてその項目の識別力(回答者の学力の高低を見分ける力)を示す指標 I−T相関(Item score - Total score)
*1「その項目の得点」と「合計得点」との相関係数・・・(1) I−R相関(Item score - Remainder score) 「その項目の得点」と「残りの項目の合計得点」との相関係数・・・(2) UL指数は上位群と下位群のデータのみを用い,中位群のデータを用いていないのに対して,点双列相関係数はすべての受検者のデータを用いる. 2* 正答率(通過率)が0または1に近いときは,識別力が低くなる. 3* 合計得点にはその項目自身の得点も含まれており,項目数が少ない場合は,(その項目自身の影響が大きくなるので)識別力が測定したいことよりも高く表示される.そこで項目数が少ないときは(2)が用いられる. ●[文献] 「教育工学事典」(実教出版株式会社/日本教育工学会編 p.228) 「項目反応理論入門」(朝倉書店/豊田秀樹著 p.6) |
例2・・・上の表1から点双列相関係数を求めるには,合計得点から各項目の得点を引いたものと各項目との相関係数を求める.(合計-各項目の欄も作っておいてまとめて相関係数を求めると一度に求められる.)
※ 通常の場合,強い相関があるとするためには相関係数として0.7とか0.8程度が期待されるが,識別力に関しては0.3以上あれば「かなりよい」とされている. I-R相関係数において0.4以上を「非常に相関がよい」,0.3以上を「かなり相関がよい」,・・,0.2未満を「相関がよくない」を目安とした. (当サイトでの実際の運用) 問題数が多いときはI-T相関を利用し,問題数が少ないときはI-R相関を利用するようにしている. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ■ 信頼性係数(クロンバックのα係数,クーダー・リチャードソンの公式(KR20)) テストの信頼性・再現性を確かめる方法として「再テスト法」「折半法」などがある. 「再テスト法」は同じ回答者にもう一度解いてもらって同じ結果が出るか否かによってテストの信頼性・再現性を確かめるものであるが,当サイトのような簡単な基本問題では1回目の答案の正誤によって2回目以降の答案が変化するのは明らかで,実際にその変化率も測定している.したがって当サイトのような問題には「再テスト法」は適さない. 「折半法」は再テストが困難な場合に,1回のテストを分割して集計することにより2回のテストを行ったと同様の効果を生むために工夫されたものでクロンバックのα係数やクーダー・リチャードソンの公式として定式化されている. しかし,これらは項目間の整合性・内的一貫性,すなわち全体として1つの能力を測定しているかどうかを示す指標で,再現性そのものの指標とは考えにくい. ●[文献] 「項目反応理論入門」(イデア出版局/高橋正規著 p.159) 「eテスティング」(培風館/植野真臣・永岡慶三著 p.27) ●[Web上の記事] http://mcn-www.jwu.ac.jp/~yokamoto/books/pm/appendices/ http://www.apec.aichi-c.ed.jp/shoko/kyouka/gakumath-h20/4.htm |
クロンバックのα係数 (=同じ値になる=) クーダー・リチャードソンの公式(KR20) (当サイトでの実際の運用) 「信頼性係数」は古典的テスト理論の重要な成果の一つであるとされているが,各項目間の整合性・一貫性は上記のI-T相関,I-R相関で調べることができ,ここでいう「信頼性係数」は再現性そのものを表わしているとは考えにくいので,当サイトではほとんど利用していない. 数百件のデータが複数回得られたときは,各項目間の正答率分布の一致についてχ2検定,同一項目の正答率の一致について分散分析で直接比較している.ただしこの場合は帰無仮説採択という消極的な結論しか得られないが,今のところもっとよい方法は思いつかない. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ■ 疑似チャンスレベル 選択問題で「まぐれで当たる」確率のこと.回答者に失礼に当たる用語だと考えるときは別の言い方をすることがある. 例えば,4択問題では「でたらめ」に答えたとき正答となる確率は25%となる. しかし,実際やってみると必ずしもそうはならない.無料のWeb教材であってもほとんどの生徒はまじめに答えるので,ある程度は確信を持って選択肢を選んでおり,生徒の好きそうな「魅力ある誤答」を知っていれば4択でも正答率が10%台になることがある. 1個の数字を記入する穴埋め問題は,10個の数字の選択問題と同じになるので,疑似チャンスレベルは10%になる. |
(当サイトでの実際の運用) 一般に,穴埋め問題にすると入力の煩わしさから回答率が悪くなる代わりに,問題作成者が想定もしない意外な誤答が回収できる利点がある. 他方で,穴埋め問題を単純な文字列照合で採点するには「全角文字・半角文字の違い」「大文字・小文字の違い」「不要なスペースの混入」などに気をつけなければならず,特に「別解の存在,許容範囲」は扱いにくい. 選択問題にすると,入力が容易で思考が途切れないから数学の内容に集中することができ,少々問題数を増やしても回答率がよくなる傾向がある. そこで,選択肢を見やすくして数を増やすと「まぐれ」が減り「回答率」が増える.回答の集まりにくい項目では積極的に選択問題にすることがある. |