|
■対応のない場合のt検定
2群の母集団平均を比較したいときに,第1群のデータと第2群のデータが「同一被験者に対する2つの条件での観測結果」「各組が兄弟の身長データ」「各組が数学の得点の等しい生徒の英語の得点」などのように,単にデータ件数が同数であるだけでなく第1群のデータと第2群のデータの間に対応がある場合は,「対応のある場合のt検定」を用いることができる.
これに対して,2群のデータ相互の間には個別の対応がない場合は「対応のない場合のt検定」を用いる. 対応のない場合のt検定は,2群の標本数が等しい場合にも等しくない場合にも使えるが,2群の分散が等しいと見なせる場合と等しいとは見なせない場合とでは適用する公式が異なるので,対応のない場合のt検定を行うためには,初めに分散が等しいと見なせるかどうかの検定(F検定)を行う.
例1
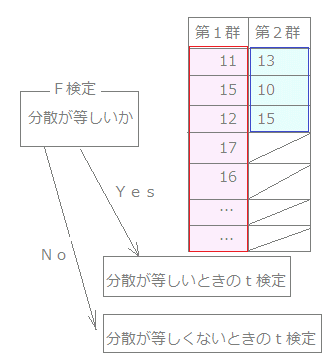
右図2は20匹の鶏のうち半数の10匹に飼料1を,残りの10匹に飼料2をそれぞれ1か月間与えたときの体重増加(g)を表しているものとする. これら2種類の飼料による体重の増加には有意差があるかどうか検定してください.
図2のデータはExcelワークシートの左上端に貼り付けるものとする.(標本の番号NoはA列,飼料1の欄はB列,飼料2の欄はC列に,これらの見出しは第1行,No1のデータは第2行に,...,No10のデータは第11行に来るものとする.)
(*) 飼料1のデータと飼料2のデータはたまたま同数になっているが,これは以下の検定の進め方に関係ない.それぞれの横の並びのデータには何も対応がないということが重要.(20匹の鶏のうち半数を飼料1に残り半数を飼料2に割り当てただけだから.)読者がデータを転記するときも,図2のデータを画面上でドラッグ→反転表示→右クリック→コピー→Excelのワークシート左上端に貼り付けるものとする.(以下の問題についても同様) (1) F検定を行う
「対応のない場合のt検定」を行うためには,あらかじめこれら2群のデータの分散が等しいと見なせるかどうか調べなければならない.Excel2010, Excel2007のとき データ→データ分析 Excel2002のとき ツール→分析ツール
→F検定:2標本を使った分散の検定→
・変数1の入力範囲(1)として B1:B11と書きこむ
(または入力欄の右にある  をクリックし,B1からB11までドラッグする.) をクリックし,B1からB11までドラッグする.)
・変数2の入力範囲(2)として C1:C11と書きこむ
(または入力欄の右にある をクリックし,C1からC11までドラッグする.)
・上記のように変数1,2の入力範囲が飼料1,飼料2というラベルを含んでいる場合は,ここで[ラベル]にチェックを付ける.
(入力範囲をB2:B11およびC2:C11としたときはこの[ラベル]にはチェックを付けない.その場合は,左にある欄が分析ルールの出力結果において「変数1」として,右にある欄が「変数2」として表示されるが,分析ツールを利用するときはラベルを含めるようにする方が見やすく分かりやすい.ただし,ラベル自体を数値の1とか2とかにすると,データ範囲と混同した時にエラーが検出されないので,ラベルには必ず文字列を使用するようにする.)
・α欄は有意水準で,デフォルトで0.05が書きこまれている(有意水準5%で検定することを表している.有意水準1%の検定を行う場合はこの数字を0.01にする.)
・何度も検定を行うときに,出力オプションを新規ワークシートや新規ブックにしているとワークシートやExcelファイルがどんどん増えてややこしくなるので,データの右側などの見やすい範囲に出力するようにするためには,「出力オプション」で「出力先」を選ぶと右の空欄が書き込めるようになるので,そこに出力したい範囲の左上端のセル番地を書きこむ.この場合,すでにあるデータが上書きされるおそれがあるときは警告が出る.
→OK右図3のような出力結果が得られる. |
図1
※Excelの「分析ツール」を利用するためには
Excel2010の場合
ファイル→オプション→アドイン→(下端の管理欄がExcelアドインとなっているときにその右の[設定]をクリック)→分析ツールにチェックを付ける→OK
Excel2007の場合
メニューのうち[ホーム]の左にある丸いOfficeボタンをクリック→下端にあるExcelのオプション→アドイン→(下端の管理欄がExcelアドインとなっているときにその右の[設定]をクリック)→分析ツールにチェックを付ける→OK
Excel2002の場合
ツール→アドイン→分析ツールにチェックを付ける→OK
図3
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
【出力結果の読み方】
⇒ 観測された分散比が1.69でF境界値片側が3.18であるから,F値が境界値よりも小さく分散には有意差が認められず,等分散とみなせる. (または,P片側が0.22で5%(0.05)よりも大きいから,分散には有意差が認められず,等分散とみなせる.) 図4 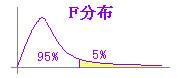 図3の例では26.681/15.75122222=1.693900297が5%境界値よりも小さいので有意差がないと判断する.この分散比は左欄に置いたデータの分散を右欄に置いたデータの分散で割ったものとなっているので,教科書通りにF検定を行うためには,分散の大きい方のデータを左欄に置かなければならない. |
しかし,どちらの分散が大きいかはやってみないと分からないので,あらかじめ分散を計算することなくF検定を行ったとき,左欄の分散が右欄の分散よりも小さくなってしまった場合には,次の図のように分散比が0に近いほど(小さいほど)分散に有意差があることになる.(分散比が1に近ければ2つの分散は等しいと見なせるが,分子が小さくなるほど分散比は0に近づく.)
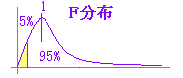 図5
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
(2) t検定を行う
上記の例では等分散となったので,「分差が等しい場合のt検定」を行う.Excel2010, Excel2007のとき データ→データ分析 Excel2002のとき ツール→分析ツール
→t
検定:等分散を仮定した2標本による検定→
・変数1の入力範囲(1)として B1:B11と書きこむ
(または入力欄の右にある をクリックし,B1からB11までドラッグする.)
・変数2の入力範囲(2)として C1:C11と書きこむ
(または入力欄の右にある をクリックし,C1からC11までドラッグする.)
・上記のように変数1,2の入力範囲が飼料1,飼料2というラベルを含んでいる場合は,ここで[ラベル]にチェックを付ける.
(入力範囲をB2:B11およびC2:C11としたときはこの[ラベル]にはチェックを付けない.
・「母集団平均が等しい」という帰無仮説に対応するためには,仮説平均との差異の欄を0にする.(平均の差が0という仮説を検定する)
(この欄は空欄のままでもデフォルトで0が入る)
・α欄は有意水準で,デフォルトで0.05が書きこまれている(有意水準5%で検定することを表している.有意水準1%の検定を行う場合はこの数字を0.01にする.)
・何度も検定を行うときに,出力オプションを新規ワークシートや新規ブックにしているとワークシートやExcelファイルがどんどん増えてややこしくなるので,データの右側などの見やすい範囲に出力するようにするためには,「出力オプション」で「出力先」を選ぶと右の空欄が書き込めるようになるので,そこに出力したい範囲の左上端のセル番地を書きこむ.この場合,すでにあるデータが上書きされるおそれがあるときは警告が出る.
→OK右図6のような出力結果が得られる.
【出力結果の読み方】
※新しい飼料2を作って,従来の飼料1よりも増量効果があるかどうかに関心があるような場合は飼料2の平均が大きいという帰無仮説をおいて片側検定を行うことになる.(片側検定か両側検定かはデータの値で決まるのでなく,分析者が何に関心があるのかによる.)
⇒ t値が-3.4で両側検定の境界値が2.1であるから,|t|>2.1となって平均に有意差がある. この分析ツールでは左欄(飼料1)の平均が右欄(飼料2)の平均よりも小さいときにt値が負(逆ならば正)で表示され,[t境界値両側]よりも絶対値が大きければ外側に来る. (または,P両側が0.003で5%(0.05)よりも小さいから有意差がある.)
帰無仮説 H0:μ1=μ2
対立仮説 H1:μ1<μ2 この場合は,出力結果のうち片側の方を見ることになる.片側検定の境界値は両側検定のときよりも内側に来るので有意差は認められやすくなる.(上記の出力結果のうち,t 境界値 片側 1.734063592,t 境界値 両側 2.100922037 を見ると片側の方が小さい.) |
図6
※ |t| の値は外側に行くほど大きくなる. 図7 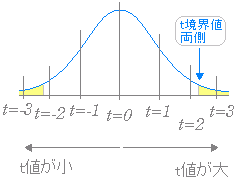 (ア) |t値|>t境界値 両側 (イ) p値<0.05 のいずれかで有意差があると判断できる. 図8 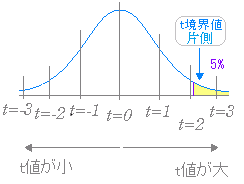 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
問題1
右の表はある学級の生徒25人(男子15人,女子10人)の数学の得点であるとする.男子と女子とで平均値に有意差があるかどうか検定してください. 空欄を埋めてください.なお,小数は第3位を四捨五入して小数第2位まで求めてください.
F検定については分析ツールを用いると次のように出力されるので,1.83, 3.03, 0.18 の順に答える.(p値の順序に注意)
|
t検定については分析ツールを用いると次のように出力されるので,2.33, 2.07, 0.03 の順に答える.(p値の順序に注意)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
問題2
右の表は2つのクラスA,Bの生徒についてある値を測定した結果だとします.これら2つのクラスの平均に有意差があるかどうか検定してください. 空欄を埋めてください.なお,小数は第3位を四捨五入して小数第2位まで求めてください.
F検定については分析ツールを用いると次のように出力されるので,3.16, 3.02, 0.04 の順に答える.(p値の順序に注意)
|
t検定については分析ツールを用いると次のように出力されるので,2.64, 2.14, 0.02 の順に答える.(p値の順序に注意)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
問題3
右の表はある教科を旧方式で指導した学級と新方式で指導した学級のテスト結果だとします.新方式の指導方法には効果があると言えるかどうか検定してください. 空欄を埋めてください.なお,小数は第3位を四捨五入して小数第2位まで求めてください.
与えられた表のままExcelの分析ツールによるF検定を行うと,新方式(右の欄)の分散の方が大きいため,次のように分散比,F境界値が1よりも小さな値で表示される.このまま判断するときは観測された分散比0.79がF境界値片側よりも大きいから分散には有意差がないと判断する.(P値は埋められるがF値は各々の逆数で答えることになる:F値は1/0.79=1.27,F片側境界値は1/0.4026=2.48,p値はそのまま0.33でよい.)
)
題意にそって分散比が1よりも大きくなるようにとるには,左欄と右欄を入れ替えてF検定を行い,下の表をもとに判断すればよい.
|
F検定により等分散と見なせるから,等分散の場合のt検定を行う.その際,左欄に旧方式の得点を置くときは左欄の平均が低いのでt値が負の値になるがその絶対値とt境界値とを比較する.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
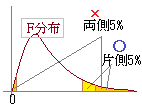 しかし,ほとんどのF検定で,分散に有意差があると見なすときは,一致する場合は含めないので,F検定は片側検定で行う.
しかし,ほとんどのF検定で,分散に有意差があると見なすときは,一致する場合は含めないので,F検定は片側検定で行う. バス代のように大人料金と小人料金で全然違う金額を集めるときは,大人の人数を数えて,子人はまとめて大人の何人分になるかと換算してから足せばよいと考える.
バス代のように大人料金と小人料金で全然違う金額を集めるときは,大人の人数を数えて,子人はまとめて大人の何人分になるかと換算してから足せばよいと考える.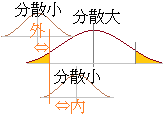 不等分散のpが0.05以下か否かは,分散の大きい側だけで判断して,平均±1.96σの範囲内に相手方の平均があるかどうか見た場合とほぼ一致する.
不等分散のpが0.05以下か否かは,分散の大きい側だけで判断して,平均±1.96σの範囲内に相手方の平均があるかどうか見た場合とほぼ一致する.