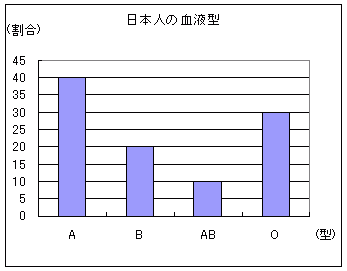
仭丂搙悢暘晍昞丆憡懳搙悢暘晍昞仭椺1仭丂塃偺僨乕僞偼丆侾妛媺40恖暘偵偮偄偰偺偁傞帋尡乮100揰枮揰乯偺摼揰偱偁傞偲偡傞丏乮悢偊傗偡偔偡傞偨傔偵彫偝偄弴偵暲傋偰偁傞丏乯偙偺僨乕僞偵偮偄偰丆搙悢暘晍昞偲僸僗僩僌儔儉傪嶌傝偨偄丏 |
丂0, 2, 15, 15, 18, 丂19, 24, 26, 27, 32, 32, 33, 40, 40, 44, 丂44, 45, 49, 52, 54, 55, 55, 59, 61, 64, 丂64, 67, 69, 70, 71, 71, 77, 80, 82, 84, 丂84, 85, 86, 91, 100 |
||||||||||||||||||||
|
亂僠僃僢僋億僀儞僩亃 仜丂奒媺偺屄悢偼彮側夁偓偰傕丆懡夁偓偰傕傛偔側偄丏 乮僌儔僼偱峫偊偰傒傞丏乯仜丂奒媺偺屄悢偼丆嵟戝抣偲嵟彫抣偺娫傪丆5乣20屄偲偐丆10乣15屄掱搙偵暘偗傞偺偑栚埨偲偝傟偰偄傞丏乮彂暔偵傛偭偰帵偝傟偰偄傞栚埨偼堎側傞偑丆偁偔傑偱栚埨偲偟偰婰壇偵偲偳傔傞丏乯 丂丂奒媺偺屄悢偺栚埨偲偟偰丆僗僞乕僕僃僗偺岞幃(仸) 仜丂奒媺偺暆偼摍娫妘偵偲傞偺偑晛捠丏 仜丂恎挿傗懱廳偺傛偆偵楢懕揑側抣傪偲傞僨乕僞傪奒媺偵暘偗傞偲偒偼丆偪傚偆偳奒媺偺嫬栚偲側傞僨乕僞偑搊応偡傞応崌偑偁傞偺偱丆0亝倶1亙10丆10亝倶2亙20丆ゥ@偺傛偆偵嫬栚偺僨乕僞傪偳偪傜偵擖傟傞偐傪偁傜偐偠傔寛傔偰偍偔丏 仜丂僸僗僩僌儔儉丂乮ゥO儔僼偱偼側偄乯 丂搙悢暘晍傪拰忬偺僌儔僼偱昞傢偟偨傕偺丏 |
恾侾
  仸丂僗僞乕僕僃僗丗恖柤 偙偺岞幃偱奒媺偺屄悢傪媮傔偨偲偒偺椺
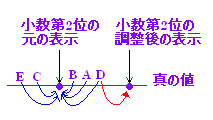
椺偊偽栺50枩恖偑庴偗傞僙儞僞乕帋尡偺摼揰暘晍傪峫偊傞偲丆偙偺岞幃偱偼 1 + log2500000丂= 栺20偲側傞偑丆幚嵺偺帒椏偱偼1揰崗傒乮101奒媺乯偱傕廫暘側傔傜偐側暘晍偲側傞丏梫偡傞偵丆乽栚埨乿偼嶲峫掱搙偲峫偊傞丏 |
| 椺侾偺埬 | |||||||||||||||
搙悢暘晍昞
|
僸僗僩僌儔儉
 |
||||||||||||||
| 嶲峫丂 | |||||||||||||||
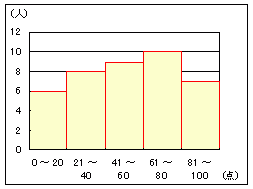
| 1 丂僗僞乕僕僃僗偺岞幃偱寁嶼偡傟偽丆N=40偺偲偒奒媺偺屄悢n偺乽栚埨乿偼栺6乣7偱偁傞偑丆95-1=94乮摼揰偼95庬椶乯傗100揰傪6乣7屄偵暘妱偡傞偲丆16揰乣14揰娫妘偺奒媺偲側傝丆偙偺暘愅傪撉傓恖偼偦偺傛偆側晄帺慠側暘妱偼岲傑偢丆10揰側偄偟20揰崗傒偺僌儔僼偵姷傟偰偄傞偲峫偊傜傟傞丏 丂10揰側偄偟20揰崗傒偵偡傞偲丆搙悢暘晍昞偐傜暯嬒抣傗昗弨曃嵎傪寁嶼偡傞偲偒偵丆奒媺偺拞墰抣偑偡偭偒傝偟偨抣偵側傞棙揰偑偁傞丏 丂10揰偲偄偆暘偗曽傪専摙偟偰傒傞偲丆師偺僌儔僼偺傛偆偵墯撌偑傂偳偔偰婯懃惈偑偒傟偄偵側傜側偄偺偱丆寢壥傪尒偰偐傜傗傔傞丏 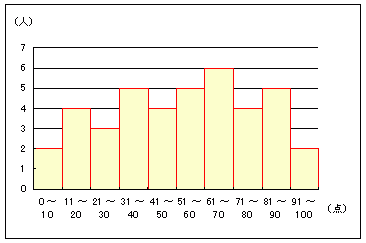 |
俀 丂恎挿傗懱廳偺傛偆側楢懕検偺応崌偼摍暘偱偒傞偑丆偙偺栤戣偺傛偆偵惍悢抣偩偗傪偲傞偲偒偼丆奺奒媺偺嬫娫偑摍偟偔側傜側偄偙偲偑偁傞丗1揰偐傜100揰偱抣偼100庬椶偱偁傞偑丆0揰偑偁傞偺偱摼揰偼101庬椶丏嵍偺椺偱偼0乣20偺奒媺偑堦屄暘懡偔側偭偰偄傞丏 俁 丂僸僗僩僌儔儉偼丆偄傢備傞朹僌儔僼偲堘偭偰廲朹偺娫偵寗娫傪嶌傜側偄丏 丂偡側傢偪丆偁傞僌儖乕僾偵偍偗傞寣塼宆暿恖悢昞丆弌恎搒摴晎導暿恖悢昞偺傛偆偵掕惈揑側暘椶乮僇僥僑儕乕僨乕僞乯傪朹僌儔僼偵偡傞偲偒偼丆壓偺恾偺傛偆偵朹偺娫偵寗娫偺偁傞僌儔僼偲偡傞丏偙傟偵懳偟偰丆杮棃偮側偑偭偰偄傞悢抣偺嬫娫傪廤寁偺搒崌偱揔摉偵暘偗偰偱偒傞僸僗僩僌儔儉偱偼丆寗娫偺側偄朹僌儔僼傪巊偆丏 丂乮Excel偱朹僌儔僼傪嶌惉偟偨偲偒丆寗娫偺側偄僌儔僼偵偡傞偵偼丆朹傪塃僋儕僢僋仺僨乕僞宯楍偺彂幃愝掕仺乮僆僾僔儑儞僞僽乯仺乽朹偺娫妘乿傪乽0乿偵偡傟偽傛偄丏乯 |
||||||||||||||