|
仭孞傝曉偟偺偁傞懳墳偺側偄擇尦攝抲偺暘嶶暘愅…椺戣丒栤戣乮Excel丆R僐儅儞僟乕偵傛傞乯 亂梡岅亃 仜丂梫場丆悈弨丆忦審
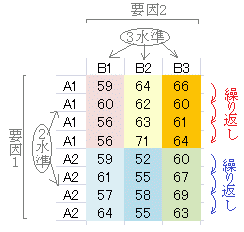
丂椺偊偽丆偐偮偍偱弌廯傪庢傞偲偒偵丆擬搾偱10暘娫媦傃15暘娫幭偨応崌丆80搙丆90搙丆100搙偺擬搾傪巊偭偨応崌偺俀亊俁捠傝偱庢偭偨弌廯偺椙偝傪怰嵏堳偵昡壙偟偰傕傜偆傕偺偲偡傞丏
丂壗暘娫幭傞偐偲偄偆戞侾偺梫場偵偮偄偰偼丆10暘娫(A1)媦傃15暘娫(A2)偺俀偮偺忦審偑偁傝丆悈弨偼俀偮偁傞偲偄偆丏 丂壗搙偱幭傞偐偲偄偆戞俀偺梫場偵偮偄偰偼丆80搙(B1)丆90搙(B2)丆100搙(B3)偲偄偆俁偮偺忦審偑偁傝丆悈弨偼俁偮偁傞偲偄偆丏 丂偙偺応崌丆幭傞帪娫乮戞侾偺梫場偲偦偺悈弨乯丆幭傞壏搙乮戞俀偺梫場偲偦偺悈弨乯傪撈棫曄悢乵愢柧曄悢乶偲偟偰怰嵏堳偺昡壙偲偄偆摼揰傪廬懏曄悢乵栚揑曄悢乶偲峫偊傞偙偲偵側傞丏 仸奺梫場偺悈弨偼丆忋偺椺偺傛偆側悢抣揑側傕偺偽偐傝偱側偔丆乽俀庬椶偺旍椏丆俁庬椶偺昪偺慻崌偣偵偮偄偰廂妌検傪挷傋傞応崌乿乽塸悢崙偺嫵壢偲巜摫曽朄偺慻崌偣偵偮偄偰帋尡偺摼揰傪挷傋傞応崌乿乽僷儞僼儗僢僩偺撪梕偲攝晍曽朄偺慻崌偣偵偮偄偰彜昳偺攧傟峴偒傪挷傋傞応崌乿偺傛偆偵柤媊揑側暘椶偱偁偭偰傕傛偄丏 仜丂擇尦攝抲丆懡尦攝抲
丂塃恾侾偱偼俀梫場乮擇尦攝抲乯偺椺傪帵偟偰偄傞偑丆俁偮埲忋偺梫場偺慻崌偣傪峫偊傞偙偲傕偱偒傞丏椺偊偽梫場侾偵偮偄偰俀悈弨丆梫場俀偵偮偄偰俀悈弨丆梫場俁偵偮偄偰俁悈弨傪峫偊傞偲偒丆俀亊俀亊俁=12屄偺忦審偵偮偄偰挷傋傞偙偲偵側傞丏偙偺傛偆側暘嶶暘愅偼懡尦攝抲偲屇偽傟傞丏
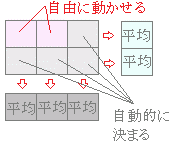
丂棟孅偺忋偱偼壗梫場乮壗尦乯偱傕偱偒傞偑丆幚嵺忋偼係梫場埲忋偵側傞偲岎屳嶌梡偺暘愅側偳偑暋嶨偵側傝夁偓傞偨傔懡尦攝抲偲偄偭偰傕嶰尦乮俁梫場乯埲壓偵偡傋偒偱偁傞偲偝傟偰偄傞丏 仜丂孞傝曉偟偺偁傞偲孞傝曉偟偺側偄偺堘偄
丂戞侾梫場俀悈弨丆戞俀梫場俁悈弨偺俀亊俁捠傝偺忦審偵偮偄偰弌廯偺椙偝傪怰嵏堳偑100揰枮揰偱昡壙偟偰丆塃恾侾偺傛偆側昞偵傑偲傔傞傕偺偲偡傞丏
丂戞侾梫場偲戞俀梫場傪慻傒崌傢偣偨侾偮偺忦審偵懳偟偰N=係恖偢偮怰嵏堳傪妱傝摉偰傞偲偒丆怰嵏堳偼俀亊俁亊係恖昁梫偲側傞丏 丂堦斒偵奺忦審偵N恖偺旐尡幰傪妱傝摉偰傞偲偒偵偼旐尡幰憤悢偼忦審偺屄悢亊N偲側傞偑丆偙偺N偑孞傝曉偟偺悢偲側傞丏 偁傞忦審偵懳偟偰寚懝僨乕僞偑偁傞応崌側偳奺忦審偵妱傝摉偰傞旐尡幰N偑摍偟偔側偄応崌乮傾儞僶儔儞僗僨僓僀儞乯偱傕孞傝曉偟偺偁傞暘嶶暘愅傪峫偊傞偙偲偑偱偒傞丏偦偺応崌偼丆奺忦審偵妱傝摉偰傜傟傞旐尡幰悢N乮孞傝曉偟偺悢乯傪挷榓暯嬒傪梡偄偰嵞寁嶼偟偨傕偺傪巊偆丏 仸Excel偺暘愅僣乕儖偱偼丆旐尡幰悢乮孞傝曉偟偺悢乯偑摍偟偔側偄暘嶶暘愅乮寚懝僨乕僞偑偁傞応崌側偳乯偼偱偒側偄丏俼僐儅儞僟乕傪巊偊偽偙偺応崌偱傕偱偒傞丏 仜丂懳墳偺偁傞偲懳墳偺側偄偺堘偄
丂梫場偑俀偮偁傞偲偒偵乮擇尦攝抲乯侾偮偺梫場傪摨堦旐尡幰偑峴偆傛偆側応崌傪懳墳偺偁傞暘嶶暘愅偲偄偄丆旐尡幰偵傛傞堘偄傪峫椂偡傞昁梫偑側偄偺偱岆嵎偑彮側偔側傝桳堄嵎偑専弌偝傟傗偡偔側傞丏
丂懳墳偺桳柍偼丆俀梫場偲傕懳墳偑桳傞応崌乮旐尡幰撪寁夋乯丆侾偮偼懳墳偑偁傝懠偺侾偮偼懳墳偑側偄応崌乮崿崌寁夋乯丆俀偮偲傕懳墳偑側偄応崌乮旐尡幰娫寁夋乯偺俁庬椶峫偊傜傟傞丏忦審偑倣亊値捠傝偁傞偲偒丆懳墳偺側偄暘嶶暘愅偱奺忦審偵俶恖偺旐尡幰傪妱傝摉偰傞応崌偼倣亊値亊俶恖偺堎側傞旐尡幰偑昁梫偲側傞丏 仸Excel偺暘愅僣乕儖丆俼僐儅儞僟乕傪巊偭偨孞傝曉偟偁傞擇尦攝抲暘嶶暘愅偼乽懳墳偺側偄応崌乿偵懳墳偟偰偍傝丆乽懳墳偺偁傞応崌乿傪挷傋傞偨傔偵偼奺帺偱寁嶼偡傞昁梫偑偁傞丏 仜丂Excel偺暘愅僣乕儖傪巊偭偰懳墳偺側偄孞傝曉偟偺偁傞擇尦攝抲暘嶶暘愅傪峴偆偲偒偺僨乕僞偺宍
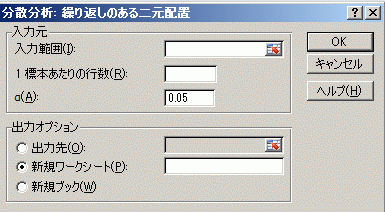
丂Excel偺暘愅僣乕儖傪巊偭偰懳墳偺側偄孞傝曉偟偺偁傞擇尦攝抲暘嶶暘愅傪峴偆偨傔偵偼丆恾侾偺傛偆側宍偺昞偵偡傞丏
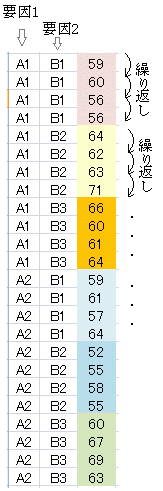
仸梫場侾偺俀偮偺悈弨柤乮A1丆A2乯偼偦偺偆偪偺愭摢偺僙儖偩偗偑廳梫偱懠偼側偔偰傕傛偄乮傕偟丆A1偲偄偆柤慜偑僨乕僞偺忋偐傜俀偮栚埲壓偺僙儖偩偗偵彂偐傟偰偄傟偽丆寢壥偺弌椡偵偍偄偰偦偺柤慜偼昞帵偝傟側偄丏乯丏A1丆A2偺柤慜奺係屄傪僙儖偺彂幃愝掕偵傛傝僙儖傪寢崌偝偣偰侾偮偵昞帵偟偰傕峔傢側偄偑丆偦偺傛偆偵偡傞昁梫偼側偄丏乮懠偺僜僼僩偵堏偟懼偊傞偙偲傕憐掕偡傞偲僙儖偺寢崌偺傛偆側Excel忋偩偗偱峴傢傟傞昞帵忋偺嵶岺偼偟側偄曽偑傛偄丏乯 仸恾侾偺僨乕僞偑儚乕僋僔乕僩嵍忋抂偵偁傞偲偒乮僙儖斣抧偺A1偐傜D9偺斖埻丏儔儀儖偲偺娭學偑暣傜傢偟偄偑丆梫場侾偺俀偮偺悈弨儔儀儖偼A楍偵梫場俀偺俁偮偺悈弨儔儀儖偼侾峴栚偵偁傞傕偺偲偡傞乯丆暘愅僣乕儖傪巊偭偰丆孞傝曉偟偺偁傞擇尦攝抲偺僟僀傾儘僌儃僢僋僗偵擖椡偡傞偵偼丆恾俀偺僟僀傾儘僌儃僢僋僗偵偍偄偰乽擖椡斖埻乿偵A1:D9傪巜掕偡傞丏乮梫場侾丆梫場俀偺悈弨柤傕擖椡斖埻偵娷傔傞傛偆偵偡傞丏乯 丂乽侾昗杮偁偨傝偺峴悢乿偵4偲彂偒偙傓ゥW杮偲偄偆尵梩偑侾慻偺昗杮乮廤崌乯傪昞偟偰偄傞偺偱侾昗杮偵偼4屄偺僨乕僞偑偁傞丏乮孞傝曉偟偺悢偑偙偺峴悢偵側偭偰偄傞丏彂暔偵傛偭偰偼丆椺悢偑4偲傕彂偐傟傞傕偺丏乯孞傝曉偟偼楍曽岦偵乮峴斣崋偑憹偊傞曽岦偵乯僙儖偑暲傫偱偄側偗傟偽側傜側偄丏 仸暘愅僣乕儖偱孞傝曉偟偺偁傞擇尦攝抲暘嶶暘愅傪峴偆偲偒偼丆孞傝曉偟偺悢偑摍偟偔側偗傟偽側傜側偄丏寚懝僨乕僞偺偁傞偲偒乮忋偱弎傋偨傾儞僶儔儞僗僨僓僀儞乯偼暘愅僣乕儖偱偼挷傋傜傟側偄丏 仜丂 俼僐儅儞僟乕傪巊偭偰懳墳偺側偄孞傝曉偟偺偁傞擇尦攝抲暘嶶暘愅傪峴偆偲偒偺僨乕僞偺宍
丂Excel忋偺僨乕僞傪僋儕僢僾儃乕僪乮Execl忋偱僐僺乕偟偰堦帪婰壇偵擖傟偨傕偺乯宱桼偱俼僐儅儞僟乕偵僀儞億乕僩偡傞偨傔偵偼丆Excel忋偺僨乕僞傪恾俁偺宍偵彂偒姺偊偰偍偔昁梫偑偁傞丏俼僐儅儞僟乕偵僀儞億乕僩偟偰巊偆偲偒偼丆昁偢偟傕塃恾俁偺傛偆偵梫場侾弴偐偮梫場俀弴偵暲傫偱偄側偔偰傕傛偔丆弴彉偼偱偨傜傔偱傕奺峴傪侾審偺僨乕僞偲尒偨偲偒偵昁梫側屄悢偑偁傟偽傛偄丏傑偨丆俼僐儅儞僟乕偱偼傾儞僶儔儞僗僨僓僀儞偱傕埖偊傞丏
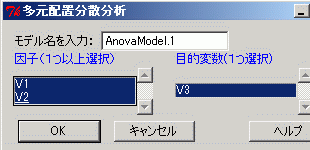
丂師偵丆偙偺僨乕僞傪僋儕僢僾儃乕僪偐傜僀儞億乕僩偡傞偵偼丆恾係偺傛偆偵乽僼傽僀儖撪偵曄悢柤偁傝乿偺僠僃僢僋傪偼偢偟偰偍偐側偗傟偽側傜側偄丏乮恾俁偺宍偺僨乕僞偺拞偵偼曄悢柤偼側偔丆俼僐儅儞僟乕偵僀儞億乕僩偝傟傞偲偒偵晅偗傜傟傞丏乯 丂嵟屻偵丆俼僐儅儞僟乕偺儊僯儏乕偐傜乵摑寁検乶仺乵暯嬒乶仺乵懡尦攝抲暘嶶暘愅乶偲恑傓偲偒偵丆乽場巕乮侾偮埲忋慖戰乯乿偺偲偙傠傪俼僐儅儞僟乕偑晅偗偨曄悢柤V1丆V2偺俀偮偲傕慖傃丆乽栚揑曄悢乮侾偮慖戰乯乿傪慖戰偡傞丏
俼僐儅儞僟乕偵僀儞億乕僩偡傞偲偒偵丆曄悢偺悈弨儔儀儖乮忋婰偺A1乣B3乯偵擔杮岅娍帤丒傂傜偑側側偳偺俀僶僀僩暥帤偑娷傑傟傞偲丆暘愅寢壥偺弌椡偺偲偒偵僄儔乕偲側傞偙偲偑偁傞傛偆偱偡丏徻偟偔偼挷傋偰偄傑偣傫偑丆儔儀儖傪侾僶僀僩暥帤偺塸悢帤偵偡傞曽偑埨慡側傛偆偱偡丏
|
恾侾丂亂Excel偺暘愅僣乕儖傪巊偭偰丆孞傝曉偟偺偁傞懳墳偺側偄擇尦攝抲偺暘嶶暘愅傪峴偆偨傔偺僨乕僞偺宍亃
     |
|
暘愅僣乕儖丆俼僐儅儞僟乕偐傜弌椡偝傟傞暘嶶暘愅昞偺尒曽
丂塃恾俇偺傛偆側僨乕僞偵偮偄偰Excel偺暘愅僣乕儖傪巊偭偰擇尦攝抲暘嶶暘愅傪峴偭偨偲偒丆媦傃塃恾俈偺傛偆側僨乕僞偵偮偄偰俼僐儅儞僟乕傪巊偭偰擇尦攝抲暘嶶暘愅傪峴偭偨偲偒丆恾俋媦傃恾10偺傛偆側暘嶶暘愅昞偑弌椡偝傟傞丏乮巻柺偺搒崌忋彫悢戞俀埵傑偱帵偡乯
偙傟傜傪妋偐傔傞偵偼丆夋柺忋偱偙偺昞偺忋傪僪儔僢僌乮斀揮昞帵乯仺乮塃僋儕僢僋乯僐僺乕仺Excel忋偵乮扨弮偵乯揬傝晅偗傞偲傛偄丏乮恾俈偺僨乕僞偼Excel忋偵揬傝晅偗偨屻偵僋儕僢僾儃乕僪宱桼偱俼僐儅儞僟乕偵僀儞億乕僩偡傞乯
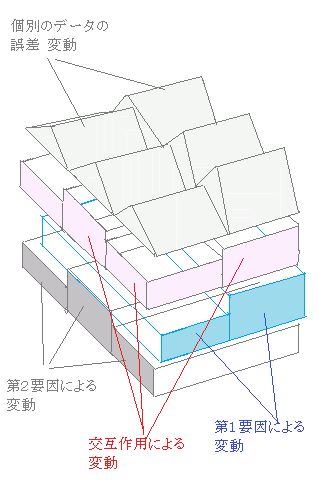
丂偙傟傜偺弌椡寢壥偲奺僨乕僞偺娭學傪弴傪捛偭偰夝愢偡傞丏乻慡懱偺棳傟乼 丂懳墳偺側偄擇尦攝抲暘嶶暘愅偱偼丆塃恾俉偺傛偆偵慡懱偺曄摦傪梫場侾偺岠壥丆梫場俀偺岠壥丆岎屳嶌梡偺岠壥丆岆嵎偵暘偗偰峫偊傞丏
乮慡曄摦乯=乮梫場1偵傛傞曄摦乯
丂師偵丆俁偮偺暘嶶斾傪媮傔傞丏+乮梫場俀偵傛傞曄摦乯 +乮岎屳嶌梡偵傛傞曄摦乯 +乮屄暿偺僨乕僞偵傛傞岆嵎乯
乮暘嶶斾侾乯= 梫場侾偺暘嶶/岆嵎偺暘嶶
丂師偵偙傟傜偺暘嶶斾偑俥専掕偺嫬奅抣傛傝傕戝偒偗傟偽乮妋棪倫偑0.05傛傝傕彫偝偗傟偽乯偦偺梫場偵偼桳堄嵎偑偁傞偲尒側偡丏乮暘嶶斾俀乯= 梫場俀偺暘嶶/岆嵎偺暘嶶 乮暘嶶斾俁乯= 岎屳嶌梡偺暘嶶/岆嵎偺暘嶶 丂偦偙偱丆暘嶶暘愅昞偼偙傟傜偺暘嶶斾傪媮傔傞偨傔偵昞傪弴偵忋偐傜壓傊丆嵍偐傜塃偵慻傒棫偰偰峴偒丆嵟廔揑偵暘嶶斾偲嫬奅抣乮傑偨偼妋棪乯傪媮傔傞傛偆偵側偭偰偄傞丏 丂俼僐儅儞僟乕偐傜偺弌椡傕偙傟偲懳墳偟偰偄傞丏偨偩偟丆俼僐儅儞僟乕偺曽偼嫬奅抣偼帵偝偢倫抣偲偦傟偑桳堄悈弨5亾偵奩摉偡傞偲偒偼*報丆1亾偵奩摉偡傞偲偒偼**報傪晅偗偰昞帵偝傟傞丏 |
|
|
乻奺乆偺悢抣乼 丂乵曄摦偺棑乶 丒慡曄摦乵暯曽榓偲傕偄偆Sum of Square, SS偲棯偝傟傞乶 =乮奺乆偺抣-慡懱偺暯嬒乯2丂偺榓
恾俇偺昞偑儚乕僋僔乕僩忋偺A1乣D9偺斖埻偵偁傞偲偒乮悢抣僨乕僞偺晹暘偑B2:D9偺斖埻偵偁傞偲偒乯ゥ葔簜蓚▊膫鄵瘲l
丒昗杮偲彂偐傟偰偄傞傕偺偼戞侾梫場偵娭偡傞傕偺丆楍偲彂偐傟偰偄傞傕偺偼戞俀梫場偵娭偡傞傕偺偵側偭偰偄傞偺偱丆戞侾梫場偵傛傞曄摦偼昗杮偲曄摦偑岎傢傞僙儖偺抣偵側傞丏慡懱偺暯嬒 m=60.92傪巊偭偰丆 (59−m)2+(60−m)2+(56−m)2+···+(63−m)2 傪寁嶼偟偨傕偺偑 499.83偵側傞丏 R僐儅儞僟乕偱偼曄悢侾偲偄偆偙偲偱V1偲彂偐傟傞傕偺偺Sum Sq丏
戞侾梫場偵娭偡傞暯嬒傪
丒戞俀梫場偵傛傞曄摦偼楍偲曄摦偑岎傢傞僙儖偺抣偵側傞丏AVERAGE(B2:D5)=61.83=mA1 AVERAGE(B6:D9)=60.00=mA2 偲彂偔偲 (mA1−m)2亊12+(mA2−m)2亊12 傪寁嶼偟偨傕偺偑 20.17偵側傞丏 R僐儅儞僟乕偱偼曄悢2偲偄偆偙偲偱V2偲彂偐傟傞傕偺偺Sum Sq丏
戞俀梫場偵娭偡傞暯嬒傪
丒戞侾梫場偲戞俀梫場偺俀亊俁慻偺奺乆偵偮偄偰乮奺乆N=4審偺僨乕僞偑偁傞乯偦偺暯嬒偲慡懱暯嬒偲偺曄摦偑岎屳嶌梡偺曄摦偵側傞丏AVERAGE(B2:B9)=59.00=mB1 AVERAGE(C2:C9)=60.00=mB2 AVERAGE(D2:D9)=63.75=mB3 偲彂偔偲 (mB1−m)2亊8+(mB2−m)2亊8+(mB3−m)2亊8 傪寁嶼偟偨傕偺偑 100.33偵側傞丏 R僐儅儞僟乕偱偼V1:V2偲彂偐傟傞丏
戞俀梫場偵娭偡傞暯嬒傪
丒慡曄摦偺偆偪偱戞侾梫場丆戞俀梫場丆岎屳嶌梡偺曄摦偵傛偭偰愢柧偱偒側偄晹暘偑岆嵎偺曄摦乮孞傝曉偟岆嵎丆屄暿偺僨乕僞偺僶儔偮偒乯偵側傞丏AVERAGE(B2:B9)=59.00=mB1 AVERAGE(C2:C9)=60.00=mB2 AVERAGE(D2:D9)=63.75=mB3 偲彂偔偲 (mB1−m)2亊8+(mB2−m)2亊8+(mB3−m)2亊8 傪寁嶼偟偨傕偺偑 100.33偵側傞丏 R僐儅儞僟乕偱偼Residuals乮巆梋乯偲彂偐傟傞丏
曄摦偺棑偱丆
乮崌寁乯=乮昗杮乯+乮楍乯+乮岎屳嶌梡乯+乮孞傝曉偟岆嵎乯 乮崌寁乯−乮昗杮乯−乮楍乯−乮岎屳嶌梡乯=乮孞傝曉偟岆嵎乯 499.83−20.17−100.33−200.33=179.00 丂乵帺桼搙偺棑乶
専掕偵偍偄偰偼丆奺乆偺曄摦偺抣偲側傞傛偆偵奺曄悢傪摦偐偟偨偲偒偵丆偦偺曄摦偺抣偑幚尰偝傟傞妋棪偑戝偒偄偐彫偝偄偐偵傛偭偰敾抐偡傞偺偱丆帺桼偵寛傔傜傟傞曄悢偺屄悢乮帺桼搙乯偼暯嬒偺悢偩偗彮側偔側傞丏
丒戞侾梫場偺曄悢偼A1丆A2偺俀屄偁傞偑丆偦傟傜偺暯嬒偑慡懱偺暯嬒偵側傞傛偆偵寛傔傞偲偒丆侾偮偺曄悢偺抣傪寛傔傞偲傕偆堦曽偺曄悢偺抣偼寛傑傞偐傜丆帺桼搙偼曄悢偺屄悢2−1偲側傞丏
戞侾梫場乮昗杮乯偺帺桼搙丂dfA=2−1=1
丒戞俀梫場偺曄悢偼B1丆B2丆B3偺俁屄偁傞偑丆偦傟傜偺暯嬒偑慡懱偺暯嬒偵側傞傛偆偵寛傔傞偲偒丆侾偮偺曄悢偺抣傪寛傔傞偲傕偆堦曽偺曄悢偺抣偼寛傑傞偐傜丆帺桼搙偼曄悢偺屄悢3−1偲側傞丏
戞俀梫場乮楍乯偺帺桼搙丂dfB=3−1=2
丒岎屳嶌梡偺曄悢偼A1B1丆A1B2丆...丆A2B3偺俇屄偁傞偑丆峴偺暯嬒媦傃楍偺暯嬒偑娤應偝傟偨抣偲側傞傛偆偵寛傔傞偲偒丆帺桼搙偼(2−1)亊(3−1)偲側傞丏
 岎屳嶌梡偺帺桼搙
岎屳嶌梡偺帺桼搙dfA×dfB=(2−1)×(3−1)=2 堦斒偵丆塃恾偺傛偆側倣亊値屄偺僙儖偺抣傪寛傔傞偲偒偵丆峴偺暯嬒丆楍偺暯嬒偑巜掕偝傟偨抣偲側傞傛偆偵寛傔傞偵偼丆(倣−1)亊(値−1)屄偺曄悢偼帺桼偵寛傔傜傟傞偑巆傝偼帺摦揑偵寛傑傞丏偟偨偑偭偰丆帺桼搙偼(倣−1)亊(値−1)偲側傞丏
孞傝曉偟岆嵎偺帺桼搙 6×3=18
丒崌寁偺帺桼搙偼偙傟傜慡晹偺榓偲側傞偑丆堦斒偵戞侾梫場偑倣屄偺曄悢丆戞俀梫場偑値屄偺曄悢丆孞傝曉偟偺屄悢N偺偲偒丆
戞侾梫場偺帺桼搙m−1
戞俀梫場偺帺桼搙n−1 岎屳嶌梡偺帺桼搙(m−1)(n−1) 孞傝曉偟岆嵎偺帺桼搙 mn(N−1) 崌寁偺帺桼搙m−1 +n−1 +nm−m−n+1 +nmN−mn =nmN−1 |
恾俉
恾10
Anova Table (Type II tests)
丂乵暘嶶偺棑乶
曄摦傪帺桼搙偱妱偭偨傕偺偑暘嶶乮晄曃暘嶶丗曣廤抍偺暘嶶偺悇掕抣乯偲側傞丏
丂乵娤應偝傟偨暘嶶斾偺棑乶
戞侾梫場丆戞俀梫場丆岎屳嶌梡偺暘嶶傪奺乆孞傝曉偟岆嵎偺暘嶶偱妱偭偨傕偺丏
丂乵俥嫬奅抣乶
奺乆偺暘嶶斾偑妋棪5亾偲側傞嫬奅抣
椺偊偽丆戞侾梫場偺暘嶶/孞傝曉偟岆嵎偺暘嶶偼丆暘巕偺帺桼搙偑1丆暘曣偺帺桼搙偑18偩偐傜丆偪傚偆偳5亾偺妋棪偲側傞暘嶶斾偼 戞侾梫場2.03<FINV(0.05,1,18)=4.41 桳堄嵎側偟 戞俀梫場5.04>FINV(0.05,2,18)=3.55 桳堄嵎偁傝 岎屳嶌梡10.07>FINV(0.05,2,18)=3.55 桳堄嵎偁傝 丂乵俹-抣乶
娤應偝傟偨暘嶶斾偑偦偺暘巕偲暘曣偵懳偟偰敪惗偡傞妋棪傪昞偡丏
乽娤應偝傟偨暘嶶斾乿偑乽俥嫬奅抣乿傛傝傕戝偒偄偐偳偆偐偱敾抐偟偰傕傛偄偑丆俹抣偑0.05傛傝傕彫偝偄偐偳偆偐敾抐偟偰傕傛偄丏 偙偺抣偼 FDIST(娤應偝傟偨暘嶶斾,丂暘巕偺帺桼搙, 暘曣偺帺桼搙) 傪寁嶼偟偨傕偺傪昞偡丏 戞侾梫場FDIST(2.03, 1, 18)=0.17>0.05 桳堄嵎側偟 戞俀梫場FDIST(5.04, 2, 18)=0.02<0.05 桳堄嵎偁傝 岎屳嶌梡FDIST(10.07, 2, 18)=0.001>0.05 桳堄嵎偁傝 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
暘嶶暘愅偺屻偺張棟偺棳傟
暘嶶暘愅昞偵偍偄偰桳堄嵎偺偁傞傕偺偑侾偮傕側偗傟偽偦傟偱廔傢偭偰偟傑偆偑丆桳堄嵎偺偁傞傕偺偑偁傞偲偒偼丆偝傜偵嬦枴偟側偗傟偽側傜側偄丏
佱屻張棟偺億僀儞僩佲
丒岎屳嶌梡偑桳堄偺偲偒偼丆庡岠壥偩偗傪嬦枴偟偰傕堄枴偑側偄偺偱悈弨暿偺奺梫場偺岠壥乮=扨弮庡岠壥乯傪嬦枴偡傞丏
丂岎屳嶌梡偑桳堄偱側偗傟偽丆奺梫場偑桳堄偐偳偆偐挷傋傟偽傛偄偑丆岎屳嶌梡偑桳堄偺応崌偼悈弨暿偺奺梫場偺岠壥乮=扨弮庡岠壥乯傪嬦枴偡傞丏丒庡岠壥傑偨偼扨弮庡岠壥偵偍偄偰桳堄嵎偺偁偭偨梫場偑俁悈弨埲忋偁傞応崌偵偼丆懡廳斾妑傪峴偆丏 丂偦偺偨傔偵丆傑偢奺悈弨暿偺暯嬒傪寁嶼偟丆塃恾11偺傛偆側愜傟慄僌儔僼傪昤偔偙偲偐傜巒傔傞丏塃恾12偺傛偆偵丆岎屳嶌梡偑側偄偲偒偼丆愜傟慄僌儔僼偑暯峴慄偵側傞偑丆侾偮偺梫場偑懠偺梫場偵媦傏偡塭嬁偑憹尭偺乽戝偒偝乿傗乽岦偒乿偵尰傟傞偲偒偼岎屳嶌梡偑偁傞丏恾11偼丆B2偺偲偙傠偱塭嬁偺岦偒偑曄壔偡傞椺偲側偭偰偄傞丏 丂偙偙偱帵偟偨椺偱偼丆戞侾梫場偼俀悈弨偱偁傞偑丆戞俀梫場偼俁悈弨偲側偭偰偄傞偺偱丆岎屳嶌梡傑偨偑戞俀梫場偵偮偄偰桳堄嵎偑偁傟偽偝傜偵懡廳斾妑傪峴偆偙偲偵側傞丏 |
亂梡岅亃 丒戞侾梫場傗戞俀梫場偵傛傞岠壥傪庡岠壥偲偄偆丏偙傟偵懳偟偰俀偮偺梫場偑慻傒崌傢偝傟偰惗偠傞岠壥傪岎屳嶌梡偲偄偆丏 丒岎屳嶌梡偑桳堄偺偲偒偼庡岠壥偩偗偱挷傋偰傕堄枴偑側偄偺偱丆悈弨暿偵暘偗偨奺梫場偺岠壥傪挷傋傞丏悈弨暿偵暘偗偨奺梫場偺岠壥傪扨弮庡岠壥偲偄偆丏 恾11 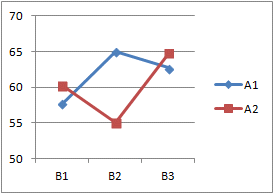 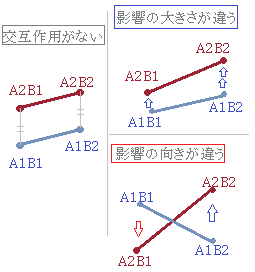 |
|
栤戣
丂塃恾13偼悢妛偲塸岅偺俀偮偺嫵壢傪俁恖偺扴摉幰T1,T2,T3偑俆恖偢偮寁俁侽恖偺惗搆偵懳偟偰屄恖巜摫偟偨偲偒偺奺惗搆偺摼揰堦棗偩偲偟傑偡丏
丂(1)丂偙偺僨乕僞偵偮偄偰Excel偺暘愅僣乕儖傪巊偭偰暘嶶暘愅傪峴偄丆嫵壢丆扴摉幰丆岎屳嶌梡偵偮偄偰挷傋偰壓偺昞傪杽傔偰偔偩偝偄丏 丂(2)丂塸岅偱扴摉幰T3偺僨乕僞乮愒帤偱帵偟偨72揰偺僨乕僞乯偑側偄偲偒乮寚懝僨乕僞偵側偭偰偄傞偲偒乯偼丆偦偙偩偗孞傝曉偟夞悢偑堎側傞偨傔Excel偺暘愅僣乕儖偱偼暘愅偱偒傑偣傫偺偱丆僨乕僞偺宍傪曄偊偰偐傜俼僐儅儞僟乕偵僀儞億乕僩偟偰暘愅偟偰偔偩偝偄丏偦偺寢壥偵偮偄偰壓偺昞傪杽傔偰偔偩偝偄丏
(1)(2)偲傕摎埬偼彫悢戞3埵傪愗傝忋偘偰彫悢戞2埵傑偱摎偊偰偔偩偝偄丏乮椺偊偽0.051偑巐幪屲擖偱0.05偲側傞偲桳堄嵎偺桳柍偑曄傢偭偰偟傑偆偺偱丆偙偙偱偼愗傝忋偘偲偟傑偡丏乯
|
恾13
(1) 師偺抣偺彫悢戞3埵傪愗傝忋偘傑偡丏 娤應偝傟偨暘嶶斾P-抣F 嫬奅抣 7.696 0.011 4.260 0.764 0.477 3.403 6.570 0.005 3.403 (2) 師偺抣偺彫悢戞3埵傪愗傝忋偘傑偡丏 F valuePr(>F) 3.1890 0.08733 4.0876 0.03027 4.8487 0.01750 |