■Rコマンダーによる主成分分析○主成分分析とは,この頁の目標主成分分析の概要については,【この頁】を参照 |
※主成分分析では,複数の変数に座標変換を行って,不偏分散が最大となるような新変数(主成分)を作る.そのとき元の変数n個で表わされる情報を幾つかの主成分に要約して表し,累積寄与率がそこそこ大きくなるところまで主成分の個数を増やしていく.
|
| ○Rコマンダーにおける主成分分析の操作手順 初めに,主成分分析に用いるデータの例を【この頁】からExcelに取り込んでおくとよい.これにより保存されたExcelファイルのいずれかのシートに,以下において利用するデータが保存されてるものとする.(日本語2バイト文字のフォルダ名,ファイル名は使用しない方がよい.)
Excel2002のとき (*1) RExcel→Start R (*2) RExcel→RComannder→with separate menus Excel2007のとき (*1)(*2)ともアドインからスタートする. |
 図2 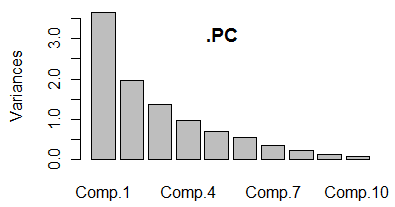 図3 表1
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
○主成分分析における主成分の個数の決め方 次のいずれかの基準で決めるのがよいとされている.
Cumulative Proportionが累積寄与率を表している.
|
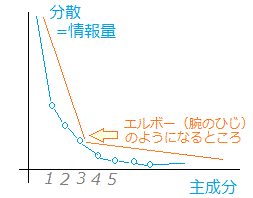
1. 図1のイメージで考えるたとき,全体の分散のうち7,8割の情報が集約できればよいと考える.完全に(100%)の情報を集約しようとすると主成分の個数が多くなり過ぎて元と変わらず,うれしくない.
2. カイザー基準とは,元のデータを標準化したデータ(相関行列から分析したとき)を用いたときに利用できる基準.この場合には,全体の分散が「変数の個数」に等しくなり,各変数の分散が「固有値の大きさ」に等しくなることを利用する.主成分に情報を集約しているのだから元の変数1個分以上となる主成分を採用するというのがカイザー基準. 3. 各主成分(component)の分散(variance)を棒グラフにすると図3のようになる.(折れ線グラフで表すことが多い.)このとき次の図のようにエルボーができた所よりも先には情報が少ないので,エルボーまでの主成分を採用するという考え方.
|
|
○主成分の命名 表2のような係数が出力されている.(10は機械的にソートされて1の次に表示されている.負の値はたまたま逆向きのベクトルになっただけでその絶対値に意味がある.) 第1主成分では項目2,5,7,9が大きい.これらは,下水道普及率,小学校教員1人当たり小学校児童数,人口千人当たり刑法犯認知件数,一人当たり県民所得の影響の大きさを表しているから,筆者は「都市型」と名付けたのであるが読者によっては他の見方があるかもしれない. 第2主成分では,項目10,4,6,8と項目2,3の影響が大きい.これらは,人口1人当たり個人預貯金残高,主要道路舗装率,交通事故死傷者数,人口10万人当たり一般病院数および下水道普及率,コンビニエンスストア数の影響を表しているから筆者は「自動車型」と名付けたのであるが読者によっては他の見方があるかもしれない. 第3主成分では,項目1,2、10および項目4の影響が強いことを表している.これらは,持ち家住宅の延べ面積,下水道普及率,個人預貯金残高および主要道路舗装率の影響を表している.筆者はこれだけでは分からないので,元のデータで項目1,10,9,4をソートしてその上位・下位に位置する県名を参考にすることにした.(表3) 核家族化の度合いとか工業化の度合いなどに関係しているのかもしれないが,第1主成分および第2主成分と無相関な都道府県力を持ってこなければならない(主成分は互いに独立であることを要す)ので,よくわからない. |
表2
表3
|