→ 携帯用は別ページ《図解,例解,実習
|
《Excelの関数》・・・解説
NORM.DIST() NORM.S.DIST() NORM.INV() NORM.S.INV() CONFIDENCE.NORM() BINOM.DIST.RANGE() |
|
正規分布の逆変換
【例R34.1】NORM.INV(確率p, 平均m, 標準偏差s) ⇒ xとする 標準正規分布の逆変換 NORM.S.INV(確率p) ⇒ zとするとき,これらの関係は \(\displaystyle z=\frac{x-m}{s}\)
\(x=m+z*s\)
NORM.INV(0.75, 8, 5) ⇒ x=11.3724・・・① このとき,次の②で計算したものは,z=(x−8)*5と等しい NORM.S.INV(0.75) ⇒ z=0.6745・・・② このとき,①で計算したものは,x=8+5*zと等しい. |
D) 生成AIを使って,直接答えを尋ねるとき
ChatGPT,Google Gemini,Microsoft Copilotのいずれでも,次のように入力した場合
【例4】
(返される答案)平均5,標準偏差3の正規分布で,x≦qとなる確率が0.65のとき,qの値は幾らか. q≒6.155が示される. |
|
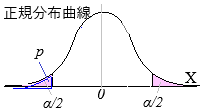
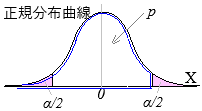
母比率のz検定(両側検定,有意水準5%)
母比率pが既知
※母集団は正規分布で,大標本とする[前提]
【例】
標本の大きさがnの大標本(概ね30以上)の場合10円硬貨を40回投げたところ,表が30回出た.この10円硬貨の表裏の出方には偏りはないと言えるか.有意水準5%で検定してください.
\(\displaystyle z=\frac{p-p_0}{\sqrt{\dfrac{p_0(1-p_0)}{n}}}\)
として,帰無仮説\(\displaystyle p=p_0\)が有意水準5%で棄却されるかどうかを,\(|z|\gt 1.96\)か否かで調べる.
A) 直接計算で求めるとき
※試験などで,コンピュータが利用できない場面で,直接計算で行う場合,±1.96という数字は覚えていなければならない.\(\displaystyle p_0=0.5,\hspace{3px}p=0.75\) \(\displaystyle z=\frac{0.75-0.5}{\sqrt{\frac{0.5*0.5}{40}}}\) \(\displaystyle z=3.162278\gt 1.96\) 有意水準5%で偏りがあると言える・・・(答) B) Rで求めるとき
Rで,(Ⅰ) 関数pnorm(z値)を使う方法 正規分布で近似してこの問題を解くには,上記の直接計算をたどりながら,関数qnormを使うと1.96という数字を覚えていなくてもできる.
正確には二項分布で行うべき問題を正規分布で近似して解いてよいための条件:\(np_0=40\times 0.5\geqq 5\)かつ\(n(1-p_0)=40\times 0.5\geqq 5\)
> n <- 40 > x <- 30 > p0 <- 0.5 > phat <- x / n > > # z値の計算(標準正規分布による近似) > z <- (phat - p0) / sqrt(p0 * (1 - p0) / n) > > # 両側p値の計算 > p_value <- 2 * (1 - pnorm(abs(z))) > > # 結果表示 > z [1] 3.162278 > p_value [1] 0.001565402p値が 0.05より小さいため、帰無仮説を棄却します。 ⇒ この10円硬貨には偏りがあるといえます・・・(答) 関数prop.test(成功回数, 試行回数, 帰無仮説の確率, alternative ="two.sided"(デフォルト)"greater"または"less", 有意水準)を使う方法
prop.test(30,40,p=0.5,alternative="two.sided")⇒ p-value = 0.002663 <0.05となって,有意水準5%で偏りがあると言える・・・(答) (Ⅱ)二項分布を利用して正確に解くには,
関数 binom.test(成功回数, 試行回数, 成功の確率 = 0.5, alternative = "two.sided",conf.level = 0.95)を使う方法
alternative = "two.sided"は両側検定を表す.
conf.levelconf.level = 0.95は信頼区間の信頼度95%を表す. binom.test(x = 30, n = 40, p = 0.5, alternative = "two.sided") ⇒ p-value = 0.002221p値が 0.05より小さいため、帰無仮説を棄却します。 ⇒ この10円硬貨には偏りがあるといえます・・・(答) C) Excelで求めるとき
●Excelで(Microsoft Excel Online, Google Spread Sheetsも同様) (Ⅰ) NORM.S.DIST(Z値, TRUE) が「標準正規分布」のZ値以下の累積確率を返すので,両側検定の場合,その2倍が有意水準よりも大きいかどうかを調べます.
\(0\)
\(x\)
\(-2\)
\(-1\)
\(1\)
\(2\)
NORM.S.DIST(Z値, TRUE)
1−NORM.S.DIST(Z値, TRUE)
\(z\)
\(\uparrow\)
\(\displaystyle z=\frac{0.75-0.5}{\sqrt{\dfrac{0.5*0.5}{40}}}=3.162278\)
0.001565<0.05により,有意水準5%で偏りがあると言える・・・(答)2*(1−NORM.S.DIST(3.1622, TRUE))=0.001565402 (Ⅱ)二項分布を利用して正確に解くには,
40回投げて:試行回数40
となる確率は,帰無仮説の確率0.5:成功率0.5 30回以上:成功回数1 30 40回以下:成功回数2 40 =BINOM.DIST.RANGE(40,0.5,30,40)⇒0.0011
40回投げて:試行回数40
となる確率は,帰無仮説の確率0.5:成功率0.5 0回以上:成功回数1 0 10回以下:成功回数2 0 =BINOM.DIST.RANGE(40,0.5,0,10)⇒0.0011 これらの和が両側確率0.0022<0.05により,有意水準5%で偏りがあると言える・・・(答) |
母比率のz検定(両側検定, 有意水準5%)
母比率p0が既知
※母集団は正規分布で,大標本とする[前提]
【例】
標本の大きさがnの大標本(概ね30以上)の場合ある提案について、無作為に100人を抽出し、調査したところ74人が「賛成」と回答しました。この回答は,2年前に実施した同種の調査で「賛成」と回答のあった割合60%と比較して変化したと言えるか、有意水準5%の両側検定で示してください。
\(\displaystyle z=\frac{p-p_0}{\sqrt{\dfrac{p_0(1-p_0)}{n}}}\)
として,帰無仮説\(\displaystyle p=p_0\)が有意水準5%で棄却されるかどうかを,\(|z|\gt 1.96\)か否かで調べる.
A) 直接計算で求めるとき
※試験などで,コンピュータが利用できない場面で,直接計算で行う場合,±1.96という数字は覚えていなければならない.\(\displaystyle p_0=0.6,\hspace{3px}p=0.74\) \(\displaystyle z=\frac{0.74-0.6}{\sqrt{\frac{0.6*0.4}{100}}}=2.857\) \(\displaystyle z\gt 1.96\)だから,60%に等しいという仮説は有意水準5%で棄却される。変化したと言える。・・・(答) B) Rで求めるとき
Rで,(Ⅰ) 関数pnorm(z値)を使う方法 正規分布で近似してこの問題を解くには,上記の直接計算をたどりながら,関数qnormを使うと1.64という数字を覚えていなくてもできる.
正確には二項分布で行うべき問題を正規分布で近似して解いてよいための条件:\(np_0=100\times 0.6\geqq 5\)かつ\(n(1-p_0)=100\times 0.4\geqq 5\)を満たしている必要がある:(満たしている)
> n <- 100 > x <- 74 > p0 <- 0.6 > phat <- x / n > > # z値の計算(標準正規分布による近似) > z <- (phat - p0) / sqrt(p0 * (1 - p0) / n) > # 片側p値の計算 > p_value <- 2*(1 - pnorm(z)) > p_value⇒ 0.0042< 0.05だから,有意差5%の片側検定で有意差があると言える。・・・(答) 関数prop.test(成功回数, 試行回数, 帰無仮説の確率, alternative ="two.sided"(デフォルト),"greater"または"less", 有意水準, correct:イェーツの連続性補正を適用するかどうか)を使う方法
※理論的なz検定と一致させるためには,「イェーツの連続性補正を適用しない:correct=FALSE」を指定する.限界値が微妙な場合に「イェーツの連続性補正を適用する(デフォルト:TRUE)」と理論的なz検定と一致しないことがある.
prop.test(74,100,p=0.6,alternative="two.sided",
⇒ p-value = 0.004267 <0.05となって,有意水準5%で高いと言える・・・(答)conf.level=0.95,correct=FALSE) (Ⅱ)二項分布を利用して正確に解くには,
関数 binom.test(成功回数, 試行回数, 成功の確率 = 0.5, alternative = "two.sided",conf.level = 0.95)を使う方法
alternative = "two.sided"は両側検定を表す.
conf.levelconf.level = 0.95は信頼区間の信頼度95%を表す.
binom.test(74, 100, p = 0.6, alternative = "two.sided")
⇒ p-value = 0.004107
p< 0.05となって,有意水準5%で高いと言える・・・(答) C) Excelで求めるとき
●Excelで(Microsoft Excel Online, Google Spread Sheetsも同様) (Ⅰ) NORM.S.DIST(Z値, TRUE) が「標準正規分布」のZ値以下の累積確率を返すので,両側検定の場合,その2倍が有意水準よりも大きいかどうかを調べます. \(\displaystyle p_0=0.6,\hspace{3px}p=0.74\) \(\displaystyle z=\frac{0.74-0.6}{\sqrt{\frac{0.6*0.4}{100}}}=2.8578\) \(\displaystyle 2*(1-\rm{NORM.S.DIST(1.6888, TRUE))}=0.00427\) < 0.05だから,正解率が等しいという仮説は有意水準5%で棄却され,有意に高いと言える・・・(答) (Ⅱ)二項分布を利用して正確に解くには,
関数
両側検定で行うために,期待値 np = 60 から +14 離れている74回と対称な左側の値の分布として,60回から −14離れた46回以下となる確率BINOM.DIST.RANGE(100,0.6,0,46)も加える.
BINOM.DIST.RANGE(試行回数,成功率,成功回数1,成功回数2) を使う方法
=BINOM.DIST.RANGE(100,0.6,74,100)
+BINOM.DIST.RANGE(100,0.6,0,46) ⇒ 0.0056<0.05となって,有意水準5%で高いと言える・・・(答) D) 生成AIを使って,直接答えを尋ねるとき
ChatGPT,Microsoft Copilot,Google Geminiで次のように入力した場合は,標本サイズが100と大きく,母比率0.66が与えられているため,そのまま1標本 z検定で答案が示される.
【例】
(返される答案)ある提案について、無作為に100人を抽出し、調査したところ74人が「賛成」と回答しました。この回答は,2年前に実施した同種の調査で「賛成」と回答のあった割合60%と比較して変化したと言えるか、有意水準5%の両側検定で示してください。 両側z検定が行われ,z=2.857>1.396により,有意差ありと判断される. |
|
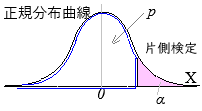
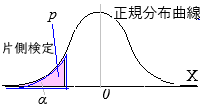
母比率のz検定(片側検定, 有意水準5%)
母比率p0が既知
※母集団は正規分布で,大標本とする[前提]
【例】
標本の大きさがnの大標本(概ね30以上)の場合ある試験問題について,A高校の生徒100人のうちで正解者は74人であった。この問題の正解率は全国平均で66%であった。この問題に対するA高校の生徒の正解率は,全国平均と比べて高いと言えるか.有意水準5%の片側検定で示してください。
\(\displaystyle z=\frac{p-p_0}{\sqrt{\dfrac{p_0(1-p_0)}{n}}}\)
として,帰無仮説\(\displaystyle p=p_0\)が有意水準5%で棄却されるかどうかを,\(z\gt 1.64\)か否かで調べる.
A) 直接計算で求めるとき
※試験などで,コンピュータが利用できない場面で,直接計算で行う場合,±1.64という数字は覚えていなければならない.\(\displaystyle p_0=0.66,\hspace{3px}p=0.74\) \(\displaystyle z=\frac{0.74-0.66}{\sqrt{\frac{0.66*0.34}{100}}}=1.6888\) \(\displaystyle z\gt 1.64\)だから,正解率が等しいという仮説は有意水準5%で棄却され,有意に高いと言える・・・(答) B) Rで求めるとき
Rで,(Ⅰ) 関数pnorm(z値)を使う方法 正規分布で近似してこの問題を解くには,上記の直接計算をたどりながら,関数qnormを使うと1.64という数字を覚えていなくてもできる.
正確には二項分布で行うべき問題を正規分布で近似して解いてよいための条件:\(np_0=100\times 0.66\geqq 5\)かつ\(n(1-p_0)=100\times 0.34\geqq 5\)を満たしている必要がある:(満たしている)
> n <- 100 > x <- 74 > p0 <- 0.66 > phat <- x / n > > # z値の計算(標準正規分布による近似) > z <- (phat - p0) / sqrt(p0 * (1 - p0) / n) > # 片側p値の計算 > p_value <- 1 - pnorm(z) > p_value [1] 0.04562876p=0.0456 < 0.05だから,有意差5%の片側検定で有意差があると言える。・・・(答) 関数prop.test(成功回数, 試行回数, 帰無仮説の確率, alternative ="two.sided"(デフォルト),"greater"または"less", 有意水準, correct:イェーツの連続性補正を適用するかどうか)を使う方法
※理論的なz検定と一致させるためには,「イェーツの連続性補正を適用しない:correct=FALSE」を指定する.限界値が微妙な場合に「イェーツの連続性補正を適用する(デフォルト:TRUE)」と理論的なz検定と一致しないことがある.
prop.test(74,100,p=0.66,alternative="greater",
⇒ p-value = 0.04563 <0.05となって,有意水準5%で高いと言える・・・(答)conf.level=0.95,correct=FALSE) |
C) Excelで求めるとき
●Excelで(Microsoft Excel Online, Google Spread Sheetsも同様) (Ⅰ) NORM.S.DIST(Z値, TRUE) が「標準正規分布」のZ値以下の累積確率を返すので,両側検定の場合,その2倍が有意水準よりも大きいかどうかを調べます. \(\displaystyle p_0=0.66,\hspace{3px}p=0.74\) \(\displaystyle z=\frac{0.74-0.66}{\sqrt{\frac{0.66*0.34}{100}}}=1.6888\) \(\displaystyle 1-NORM.S.DIST(1.6888, TRUE)=0.0456\lt 0.05\)だから,正解率が等しいという仮説は有意水準5%で棄却され,有意に高いと言える・・・(答) (Ⅱ)二項分布を利用して正確に解くには,
関数
BINOM.DIST.RANGE(試行回数,成功率,成功回数1,成功回数2) を使う方法
実は,この方法で行うと,微妙なところで有意差が認められない.Rのbinom.testでも同様.
D) 生成AIを使って,直接答えを尋ねるとき
ChatGPT,Microsoft Copilot,Google Geminiで次のように入力した場合は,標本サイズが100と大きく,母比率0.66が与えられているため,そのまま1標本 z検定で答案が示される.
【例】
(返される答案)ある試験問題について,A高校の生徒100人のうちで正解者は74人であった。この問題の正解率は全国平均で66%であった。この問題に対するA高校の生徒の正答率は,高いと言えるか.有意水準5%の片側検定で示してください。 有意水準5%の片側検定の結果、A高校の正答率は全国平均66%よりも有意に高いと判断されます。 |
|
|