≪いっしょにPython≫ プログラマーの実験ノート
このページは,プログラム言語Pythonをこれから学ぼうと考えている筆者の備忘録です.そこそこ調べて書いていますが,仕様を精密に調べたものではありません.どちらかと言えば,実装されたPython 3を使ってみてどうなったかということを中心に書いたものです.いわば,実験ノートの記録です.
参考:このページでは,括弧(かっこ)を次のように読むことにする
• ( ) … かっこ,小かっこ,パーレン(単数形=parenthesis,複数形=parentheses)
• { } … 波かっこ,中かっこ,ブレース(brace)
• [ ] … 角かっこ,大かっこ,ブラケット(bracket)
• < > … 山かっこ,(angle bracket)
• ( ) … かっこ,小かっこ,パーレン(単数形=parenthesis,複数形=parentheses)
• { } … 波かっこ,中かっこ,ブレース(brace)
• [ ] … 角かっこ,大かっこ,ブラケット(bracket)
• < > … 山かっこ,(angle bracket)
1. タプル(tuple)の作成
(1) ( )で囲んで,カンマで区切って書く
• タプルは作成された後,要素を追加,削除,変更されない.(イミュータブルな型)
• 上記の性質があるので,一見不便に見えるが,間違って書き換えられないので安全に使える.
• 上記の性質があるので,一見不便に見えるが,間違って書き換えられないので安全に使える.
【例 1.1】
>>> tp1 = ('Jan','Feb','Mar')
>>> tp1
→ ('Jan','Feb','Mar') (タプルの名前を入力すれば,中身を確かめられる)
>>> tp1[2]
→ 'Mar' (タプルの要素は,オフセット[先頭を0とする番号]で取り出せる)
>>> tp1 = ('Jan','Feb','Mar')
>>> tp1
→ ('Jan','Feb','Mar') (タプルの名前を入力すれば,中身を確かめられる)
>>> tp1[2]
→ 'Mar' (タプルの要素は,オフセット[先頭を0とする番号]で取り出せる)
(2) ( )で囲まずに,カンマで区切ってもタプルの定義になる
【例 1.2】
>>> tp2 = 'Apr','May','Jun', (かっこを省略して,カンマで書き並べるとタプルになる.最後のカンマは省略してもよい)
>>> tp2
→ ('Apr', 'May', 'Jun') (入力時にかっこを省略していても,タプルとしてかっこが付く)
>>> tp2 = 'Apr','May','Jun', (かっこを省略して,カンマで書き並べるとタプルになる.最後のカンマは省略してもよい)
>>> tp2
→ ('Apr', 'May', 'Jun') (入力時にかっこを省略していても,タプルとしてかっこが付く)
(3) tuple()関数を使って,他の型からタプルを作ることができる
【例 1.3】
>>> str1='abcd'
>>> tp1 = tuple(str1)
>>> tp1
→ ('a', 'b', 'c', 'd') (文字列からタプルを作ると,1文字ずつバラバラになる)
>>> str1='abcd'
>>> tp1 = tuple(str1)
>>> tp1
→ ('a', 'b', 'c', 'd') (文字列からタプルを作ると,1文字ずつバラバラになる)
>>> str2 = 'I am a boy.'
>>> tp2 = tuple(str2)
>>> tp2
→ ('I', ' ', 'a', 'm', ' ', 'a', ' ', 'b', 'o', 'y', '.') (スペース区切りの単語から成る文字列でも,1文字ずつバラバラになる)
>>> tp2 = tuple(str2)
>>> tp2
→ ('I', ' ', 'a', 'm', ' ', 'a', ' ', 'b', 'o', 'y', '.') (スペース区切りの単語から成る文字列でも,1文字ずつバラバラになる)
>>> L1 = ['Sun','Mon','Tue']
>>> tp3 = tuple(L1)
>>> tp3
→ ('Sun', 'Mon', 'Tue') (リストからタプルを作ると,各要素ごとに入る)
>>> tp3 = tuple(L1)
>>> tp3
→ ('Sun', 'Mon', 'Tue') (リストからタプルを作ると,各要素ごとに入る)
2. タプルの要素にできること,できないこと
(1) オフセットを使った読み出し
【例 2.1】
>>> tp1 = ('Sun','Mon','Tue')
>>> tp1[1]
→ 'Mon' (タプルの要素はオフセット[先頭を0番とする番号]で読み出せる)
>>> tp1 = ('Sun','Mon','Tue')
>>> tp1[1]
→ 'Mon' (タプルの要素はオフセット[先頭を0番とする番号]で読み出せる)
>>> tp1 = ('Sun','Mon','Tue')
>>> tp1[1] = 'Fri'
→ エラー (タプルを定義して後,個別の要素を書き換えることはできない.タプルの要素を代入文の左辺に置くことはできない.)
>>> tp1[1] = 'Fri'
→ エラー (タプルを定義して後,個別の要素を書き換えることはできない.タプルの要素を代入文の左辺に置くことはできない.)
>>> tp1 = ('Sun','Mon','Tue')
>>> tp2 = ('Wed', 'Thu', 'Fri', 'Sat')
>>> tp1 = tp2 (タプルを丸ごと再定義することは可能)
>>> tp1
→ ('Wed', 'Thu', 'Fri', 'Sat')
>>> tp2 = ('Wed', 'Thu', 'Fri', 'Sat')
>>> tp1 = tp2 (タプルを丸ごと再定義することは可能)
>>> tp1
→ ('Wed', 'Thu', 'Fri', 'Sat')
(2) 調べること→○,変更すること→×
【例 2.2.1】
>>> tp1 = ('Sun','Mon','Tue','Sun')
>>> len(tp1)
→ 4 (関数len()を使ってタプルの要素数を調べることはできる)
>>> tp1 = ('Sun','Mon','Tue','Sun')
>>> len(tp1)
→ 4 (関数len()を使ってタプルの要素数を調べることはできる)
>>> tp1 = ('Sun','Mon','Tue','Sun')
>>> tp1.count('Sun')
→ 2 (count(str)メソッドを使って,strに一致する要素数を調べることはできる)
>>> tp1.count('Sun')
→ 2 (count(str)メソッドを使って,strに一致する要素数を調べることはできる)
>>> tp1 = ('Sun','Mon','Tue','Sun')
>>> tp1.index('Sun')
→ 0 (index(str)メソッドを使って,strに一致する最初の要素のオフセットを調べることはできる)
>>> tp1.index('Sun')
→ 0 (index(str)メソッドを使って,strに一致する最初の要素のオフセットを調べることはできる)
>>> tp1 = ('Sun','Mon','Tue','Sun')
>>> 'Tue' in tp1
→ True (in演算子を使って,ある要素がタプルの中にあるか無いかを調べることはできる)
>>> 'Tue' in tp1
→ True (in演算子を使って,ある要素がタプルの中にあるか無いかを調べることはできる)
【例 2.2.2】
>>> tp1 = ('Sun','Mon','Tue')
>>> tp1.sppend('Wed')
→ エラー (append()メソッドを使って要素を追加[変更の一種]することはできない)
>>> tp1 = ('Sun','Mon','Tue')
>>> tp1.sppend('Wed')
→ エラー (append()メソッドを使って要素を追加[変更の一種]することはできない)
>>> tp1 = ('Sun','Mon','Tue')
>>> tp2 = ('Wed','Thu')
>>> tp1.extend(tp2)
→ エラー (extend()メソッドを使って,タプルを結合[変更の一種]することはできない)
>>> tp2 = ('Wed','Thu')
>>> tp1.extend(tp2)
→ エラー (extend()メソッドを使って,タプルを結合[変更の一種]することはできない)
>>> tp1 = ('Sun','Mon','Tue')
>>> tp1.sort()
→ エラー (sort()メソッドを使って,タプルの要素を並べ替える[変更の一種]ことはできない)
>>> tp1.sort()
→ エラー (sort()メソッドを使って,タプルの要素を並べ替える[変更の一種]ことはできない)
>>> tp1 = ('Sun','Mon','Tue')
>>> tp1.insert(1, 'Wed')
→ エラー (insert()メソッドを使って,タプルに要素を挿入する[変更の一種]ことはできない)
>>> tp1.insert(1, 'Wed')
→ エラー (insert()メソッドを使って,タプルに要素を挿入する[変更の一種]ことはできない)
>>> tp1 = ('Sun','Mon','Tue')
>>> tp1.remove('Mon')
→ エラー (remove()メソッドを使って,タプルの要素を削除する[変更の一種]ことはできない)
※ pop(), delもない
>>> tp1.remove('Mon')
→ エラー (remove()メソッドを使って,タプルの要素を削除する[変更の一種]ことはできない)
3. 複数要素の代入
タプルを使えば,n次元ベクトルの成分を扱うように,一度に多数の変数に代入することができます.
【例 3.1】
>>> tp1 = (3.14, 2.51, 1.41)
>>> x, y, z = tp1
>>> print(x, y, z)
→ 3.14 2.51 1.41
>>> tp1 = (3.14, 2.51, 1.41)
>>> x, y, z = tp1
>>> print(x, y, z)
→ 3.14 2.51 1.41
>>> tp1 = ('Sun','Mon','Tue')
>>> a, b = tp1
→ エラー (要素の個数が合わないとエラーになる)
>>> a, b, c, d = tp1
→ エラー (要素の個数が合わないとエラーになる)
>>> a, b = tp1
→ エラー (要素の個数が合わないとエラーになる)
>>> a, b, c, d = tp1
→ エラー (要素の個数が合わないとエラーになる)
4. タプルの代入は値渡し
タプルを定義してから後に,その要素を書き換えることはできないが,タプルを丸ごと再定義することはできる.
「リスト,辞書,集合のようなミュータブルな型」で1つの変数を他の変数に代入すると,その変数の参照(メモリのアドレス)が渡されるので,2つの変数は連動し,一方の要素を書き換えると他方の要素も書き換わる.
これに対して,「int, float, 文字列,タプルのようなイミュータブルな型」で1つの変数を他の変数に代入すると,その値が渡されるので,2つの変数は連動せず,一方を書き換えても他方は影響を受けない.
「リスト,辞書,集合のようなミュータブルな型」で1つの変数を他の変数に代入すると,その変数の参照(メモリのアドレス)が渡されるので,2つの変数は連動し,一方の要素を書き換えると他方の要素も書き換わる.
これに対して,「int, float, 文字列,タプルのようなイミュータブルな型」で1つの変数を他の変数に代入すると,その値が渡されるので,2つの変数は連動せず,一方を書き換えても他方は影響を受けない.
【例 4.1】
>>> tp1 = ('a','b','c')
>>> tp2 = ('x','y')
>>> tp3 = tp1 (tp3はtp1の値を使って定義する)
>>> tp1 = tp2 (tp1はを再定義する)
>>> print(tp1,tp2,tp3) → ('x', 'y') ('x', 'y') ('a', 'b', 'c') (tp1を再定義してもtp3の値は変化しない)
>>> tp1 = ('a','b','c')
>>> tp2 = ('x','y')
>>> tp3 = tp1 (tp3はtp1の値を使って定義する)
>>> tp1 = tp2 (tp1はを再定義する)
>>> print(tp1,tp2,tp3) → ('x', 'y') ('x', 'y') ('a', 'b', 'c') (tp1を再定義してもtp3の値は変化しない)
Pythonを含む様々なプログラミング言語において,変数xとyの「値の交換」を行いたいとき,
x = y
y = x
などとすることはできない.このようなやり方では,1行目の段階でxの値が書き換わってしまうため,2行目で書き換わった後のxの値(初めのyの値)がyに代入され,x,yとも同じ値になってしまう.これを避けるためには,通常,第3の変数に一時的にxの値を退避させておいてから戻す.y = x
w = x
x = y
y = w
一般のプログラミング言語では,以上のような方法で変数の値の交換を行うのが普通であるが,Pythonのタプルでは「代入は値渡し」で行われるので,次のように一度にx,yを交換することができる.x = y
y = w
(x, y) = (y, x)
【例 4.2】
>>> a = 3
>>> b = -4
>>> (a, b) = (b, a)
>>> print(a,b)
→ -4 3
>>> a = 3
>>> b = -4
>>> (a, b) = (b, a)
>>> print(a,b)
→ -4 3
5. 辞書(dict)の作成
(1) {キー1:値1, キー2:値2, ... }による辞書の作成
• 辞書はブレース(波かっこ)を使って表し,キー:値の組をカンマで区切って書き並べます.
• 値として使えるデータの型には制限がないが,キーとして使えるデータの型は「数値,文字列,タプル」などのイミュータブル(定義後に書き換えできない)な型に限られ,「リスト,集合さらには辞書自体」はミュータブル(定義後に書き換え可能)な型なので,キーとしては使えない.
• キーは,数値だけ,とか,文字列だけのように同質の型である必要はなく,数値,文字列,タプルなどが1つの辞書のキーとして併存できる.
• 値として使えるデータの型には制限がないが,キーとして使えるデータの型は「数値,文字列,タプル」などのイミュータブル(定義後に書き換えできない)な型に限られ,「リスト,集合さらには辞書自体」はミュータブル(定義後に書き換え可能)な型なので,キーとしては使えない.
• キーは,数値だけ,とか,文字列だけのように同質の型である必要はなく,数値,文字列,タプルなどが1つの辞書のキーとして併存できる.
【例 5.1】
>>> dic1 = {'03':'東京', '06':'大阪', '075':'京都'}
>>> dic1
→ {'03': '東京', '06': '大阪', '075': '京都'} (辞書の名前を入力すると,キー:値のすべての組が表示されます) >>> dic1['06']
→ '大阪' (キーを入れると値が返されます)
>>> d1
→ {1: 'a', 'b': 0, (2, 3): ['c', 'd']}
(「数値,文字列,タプル」がキーとして併存でき,値には「リスト」も入ってもよい)
>>> dic1 = {'03':'東京', '06':'大阪', '075':'京都'}
>>> dic1
→ {'03': '東京', '06': '大阪', '075': '京都'} (辞書の名前を入力すると,キー:値のすべての組が表示されます) >>> dic1['06']
→ '大阪' (キーを入れると値が返されます)
>>> dic1 = {'03':'東京', '06':'大阪', '075':'京都', '075':'山崎'}
>>> dic1
→ {'03': '東京', '06': '大阪', '075': '京都'} (辞書の名前を入力すると,キー:値のすべての組が表示されます) >>> dic1['06']
→ '大阪' (キーを入れると値が返されます)
>>> dic1
→ {'03': '東京', '06': '大阪', '075': '京都'} (辞書の名前を入力すると,キー:値のすべての組が表示されます) >>> dic1['06']
→ '大阪' (キーを入れると値が返されます)
dic1 = {'03':'東京','06':'大阪','075':'京都','073':'京都'}
>>> dic1
→ {'03': '東京', '06': '大阪', '075': '京都', '073': '京都'}
(異なるキーが同じ値に対応している辞書は可能です.[多対1対応はかまわない])
>>> dic1
→ {'03': '東京', '06': '大阪', '075': '京都', '073': '京都'}
(異なるキーが同じ値に対応している辞書は可能です.[多対1対応はかまわない])
>>> dic1 = {'03':'東京', '06':'大阪', '075':'京都', '075':'山崎'}
>>> dic1
→ {'03': '東京', '06': '大阪', '075': '山崎'}
(同じキーに異なる値を対応させて定義したときは,後出しの勝ちとします.)
(すなわち,辞書では同じキーは存在できません.間違って同じキーを書いたときは,後から書かれたキー:値の組によって上書きされます)
>>> d1 = {1:'a','b':0,(2,3):['c','d']}>>> dic1
→ {'03': '東京', '06': '大阪', '075': '山崎'}
(同じキーに異なる値を対応させて定義したときは,後出しの勝ちとします.)
(すなわち,辞書では同じキーは存在できません.間違って同じキーを書いたときは,後から書かれたキー:値の組によって上書きされます)
>>> d1
→ {1: 'a', 'b': 0, (2, 3): ['c', 'd']}
(「数値,文字列,タプル」がキーとして併存でき,値には「リスト」も入ってもよい)
(2) dict()関数を使った辞書の作成
2つの要素が組になっているデータをdict()関数で取り込むと,辞書が作れる.
【例 5.2】
元データが文字列のリストである場合
>>> Ls1 =['1x','2y','A4','2z']
>>> d1 = dict(Ls1)
>>> d1
→ {'1': 'x', '2': 'z', 'A': '4'} (前後で前がキーになるが,同じキー2が登場したので,後で登場した'2':'z'で上書きされて,'2':'y'は消える)
元データが文字列のリストである場合
>>> Ls1 =['1x','2y','A4','2z']
>>> d1 = dict(Ls1)
>>> d1
→ {'1': 'x', '2': 'z', 'A': '4'} (前後で前がキーになるが,同じキー2が登場したので,後で登場した'2':'z'で上書きされて,'2':'y'は消える)
元データがリストのリストである場合
>>> pair1 = [[1, 'a'],[2, 'b'],[3, 'c'],[4, 'd']]
>>> d1 = dict(pair1)
>>> d1
→ {1: 'a', 2: 'b', 3: 'c', 4: 'd'} (2つずつ組なっているデータは前をキーとし,後ろを値とする辞書にできる)
>>> pair1 = [[1, 'a'],[2, 'b'],[3, 'c'],[4, 'd']]
>>> d1 = dict(pair1)
>>> d1
→ {1: 'a', 2: 'b', 3: 'c', 4: 'd'} (2つずつ組なっているデータは前をキーとし,後ろを値とする辞書にできる)
6. 辞書の要素の追加
(1) 辞書[キー] = 値による追加
【例 6.1】
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d1['ほ'] = '北海道'
>>> d1
→ {'と': '東京', 'お': '大阪', 'き': '京都', 'ほ': '北海道'}
(この例では,たまたま末尾に追加されたが,辞書の中では各要素の順番というものは決まっておらず,キーで区別されているだけ.辞書を表示するたびに順序が入れ替わっていることもある)
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d1['ほ'] = '北海道'
>>> d1
→ {'と': '東京', 'お': '大阪', 'き': '京都', 'ほ': '北海道'}
(この例では,たまたま末尾に追加されたが,辞書の中では各要素の順番というものは決まっておらず,キーで区別されているだけ.辞書を表示するたびに順序が入れ替わっていることもある)
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d1['お'] = '岡山'
>>> d1
→ {'と': '東京', 'お': '岡山', 'き': '京都'} (同じキーで別の値を持つ要素を追加すると,上書きされて元の値は消える)
>>> d1['お'] = '岡山'
>>> d1
→ {'と': '東京', 'お': '岡山', 'き': '京都'} (同じキーで別の値を持つ要素を追加すると,上書きされて元の値は消える)
(2) 辞書1.update(辞書2)による他の辞書の結合
【例 6.2】
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d2 = {'と':'富山','い':'石川'}
>>> d1.update(d2)
>>> d1
→ {'と': '富山', 'お': '大阪', 'き': '京都', 'い': '石川'}
(同じキーの'と'があるから,元の値'東京'は消えて'富山'が残る)
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d2 = {'と':'富山','い':'石川'}
>>> d1.update(d2)
>>> d1
→ {'と': '富山', 'お': '大阪', 'き': '京都', 'い': '石川'}
(同じキーの'と'があるから,元の値'東京'は消えて'富山'が残る)
(3) 辞書1 = 辞書2.copy()による他の辞書の内容のコピー
【例 6.3】
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d2 = d1.copy()
>>> d2
→ {'と': '東京', 'お': '大阪', 'き': '京都'}
>>> d1['お'] = '岡山'
>>> d2
→ {'と': '東京', 'お': '大阪', 'き': '京都'}
(d2はd1の内容をコピーした別の辞書なので,d1を書き換えてもd2は変わらない)
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d2 = d1.copy()
>>> d2
→ {'と': '東京', 'お': '大阪', 'き': '京都'}
>>> d1['お'] = '岡山'
>>> d2
→ {'と': '東京', 'お': '大阪', 'き': '京都'}
(d2はd1の内容をコピーした別の辞書なので,d1を書き換えてもd2は変わらない)
(4) 辞書1 = 辞書2による他の辞書の参照(メモリアドレス)のコピー
「リスト,辞書,集合のようなミュータブルな型」で1つの変数を他の変数に代入すると,その変数の参照(メモリのアドレス)が渡されるので,2つの変数は連動し,一方の要素を書き換えると他方の要素も書き換わる.
【例 6.4】
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d2 = d1 (参照のコピー)
>>> d2
→ {'と': '東京', 'お': '大阪', 'き': '京都'}
>>> d1['お'] = '岡山'
>>> d2
→ {'と': '東京', 'お': '岡山', 'き': '京都'}
(d2はd1と同じアドレスになるから,d1を書き換えるとd2も変わる)
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d2 = d1 (参照のコピー)
>>> d2
→ {'と': '東京', 'お': '大阪', 'き': '京都'}
>>> d1['お'] = '岡山'
>>> d2
→ {'と': '東京', 'お': '岡山', 'き': '京都'}
(d2はd1と同じアドレスになるから,d1を書き換えるとd2も変わる)
7. 辞書の要素の削除
(1) del 辞書[キー]による特定要素の削除
【例 7.1】
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> del d1['と']
>>> d1
→ {'お':'大阪','き':'京都'}
('と'をキーとする要素[キーと値の両方]を削除)
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> del d1['と']
>>> d1
→ {'お':'大阪','き':'京都'}
('と'をキーとする要素[キーと値の両方]を削除)
(2) 辞書.clear()による辞書の全部の要素の削除
【例 7.2】
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d1.clear()
>>> d1
→ {}
(要素が空の辞書は残る)
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d1.clear()
>>> d1
→ {}
(要素が空の辞書は残る)
(3) 辞書 = {}による辞書の再定義
【例 7.3】
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d1 = {}
>>> d1
→ {}
(要素が空の辞書は残る)
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d1 = {}
>>> d1
→ {}
(要素が空の辞書は残る)
8. 辞書の要素の検査,表示
(1) キー in 辞書による要素の有(True)無(False)の検査
【例 8.1】
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> 'お' in d1
→ True ('お'をキーとする要素はあるから,Trueが返される)
>>> '東京' in d1
→ false (値の方で一致しても関係ない)
>>> 'あ' in d1
→ false ('あ'をキーとする要素はないから,Falseが返される)
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> 'お' in d1
→ True ('お'をキーとする要素はあるから,Trueが返される)
>>> '東京' in d1
→ false (値の方で一致しても関係ない)
>>> 'あ' in d1
→ false ('あ'をキーとする要素はないから,Falseが返される)
(2) 辞書[キー]による要素の取り出し
【例 8.2】
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d1['お']
→ '大阪'
>>> d1[1]
→ エラー (辞書では,リストやタプルと違ってオフセット[先頭からの番号]は決まっていない.呼び出すたびに違う順に表示される場合もある.辞書はキーという名札を持って座っている群衆のような感じで,キーに一致するかどうかだけが手がかり)
>>> d1['あ']
→ エラー (存在しないキーで読み出すと,Falseではなく,エラーになる)
>>> d1 = {'と':'東京','お':'大阪','き':'京都'}
>>> d1['お']
→ '大阪'
>>> d1[1]
→ エラー (辞書では,リストやタプルと違ってオフセット[先頭からの番号]は決まっていない.呼び出すたびに違う順に表示される場合もある.辞書はキーという名札を持って座っている群衆のような感じで,キーに一致するかどうかだけが手がかり)
>>> d1['あ']
→ エラー (存在しないキーで読み出すと,Falseではなく,エラーになる)
(3) 辞書.keys()によるすべてのキーの取り出し
【例 8.3】
>>> d1 = {'東京':'関東','千葉':'関東','大阪':'関西','京都':'関西'}
>>> d1.keys()
→ dict_keys(['東京', '千葉', '大阪', '京都'])
(dict_keys()オブジェクトの引数として,すべてのキーが返される)
>>> d1 = {'東京':'関東','千葉':'関東','大阪':'関西','京都':'関西'}
>>> d1.keys()
→ dict_keys(['東京', '千葉', '大阪', '京都'])
(dict_keys()オブジェクトの引数として,すべてのキーが返される)
(4) 辞書.values()によるすべての値の取り出し
【例 8.4】
>>> d1 = {'東京':'関東','千葉':'関東','大阪':'関西','京都':'関西'}
>>> d1.values()
→ dict_values(['関東', '関東', '関西', '関西'])
(dict_values()オブジェクトの引数として,すべての値が返される.重複があれば重複のまま返される.)
>>> d1 = {'東京':'関東','千葉':'関東','大阪':'関西','京都':'関西'}
>>> d1.values()
→ dict_values(['関東', '関東', '関西', '関西'])
(dict_values()オブジェクトの引数として,すべての値が返される.重複があれば重複のまま返される.)
(5) 辞書.items()によるすべてのキーと値の取り出し
【例 8.5】
>>> d1 = {'東京':'関東','千葉':'関東','大阪':'関西','京都':'関西'}
>>> d1.items()
→ dict_items([('東京', '関東'), ('千葉', '関東'), ('大阪', '関西'), ('京都', '関西')])
(単に辞書の名前を入力した場合 d1 とよく似ているが,キーと値がタプルの組となるところが異なる.)
>>> d1 = {'東京':'関東','千葉':'関東','大阪':'関西','京都':'関西'}
>>> d1.items()
→ dict_items([('東京', '関東'), ('千葉', '関東'), ('大阪', '関西'), ('京都', '関西')])
(単に辞書の名前を入力した場合 d1 とよく似ているが,キーと値がタプルの組となるところが異なる.)
9. 辞書を使ったイテレーション(反復処理,ループ)
(1) for キー in 辞書:
【例 9.1】
>>> d1 = {'新聞代':4000,'電話代':5000,'本代':2000,'食費':15000}
>>> for k1 in d1:
print(d1[k1],end=' ')
→ 4000 5000 2000 15000
(8.(1)と同様に、単に「k1 in 辞書」とすれば,辞書のキーにk1があるか無いかを調べる.それがTrueのとき,d1[k1]により辞書の値が読みだされる)
>>> d1 = {'新聞代':4000,'電話代':5000,'本代':2000,'食費':15000}
>>> for k1 in d1:
print(d1[k1],end=' ')
→ 4000 5000 2000 15000
(8.(1)と同様に、単に「k1 in 辞書」とすれば,辞書のキーにk1があるか無いかを調べる.それがTrueのとき,d1[k1]により辞書の値が読みだされる)
(2) for キー in 辞書.keys():
【例 9.2】
>>> d1 = {'新聞代':4000,'電話代':5000,'本代':2000,'食費':15000}
>>> for k1 in d1.keys():
print(d1[k1],end=' ')
→ 4000 5000 2000 15000
(上記と同じことになる)
>>> d1 = {'新聞代':4000,'電話代':5000,'本代':2000,'食費':15000}
>>> for k1 in d1.keys():
print(d1[k1],end=' ')
→ 4000 5000 2000 15000
(上記と同じことになる)
(3) for キー in 辞書.values():
【例 9.3】
>>> d1 = {'新聞代':4000,'電話代':4000,'本代':2000,'食費':15000}
>>> for v1 in d1.values():
print(v1,end=' ')
→ 4000 4000 2000 15000
(辞書の値で検索するには,辞書.values()がTrueになるかどうかで判断する.この例のように,値の方は重複する場合があり,重複がある場合は重複して登場する)
>>> d1 = {'新聞代':4000,'電話代':4000,'本代':2000,'食費':15000}
>>> for v1 in d1.values():
print(v1,end=' ')
→ 4000 4000 2000 15000
(辞書の値で検索するには,辞書.values()がTrueになるかどうかで判断する.この例のように,値の方は重複する場合があり,重複がある場合は重複して登場する)
(*) メモ:辞書の要素をキー順にソートするには
IDLE → New File → Save as .. → Run
【例 9.4】• 辞書の要素数が数百件あって,何かの都合でキー順にソートしたいとき
dic1 = {3:'arm', 2:'am', 1:'a', 4:'aunt'} list1 = list(dic1)#1 list2 = sorted(list1)#2 dic2 = {} for xx in list2: dic2[xx] = dic1[xx]#3 print(dic2)
• list(辞書)で辞書のうちのキーだけのリストになる
• sorted(リスト)でソートしたリストができる • dic2[キー] = dic1[キー]で,dic2に{キー:dic1で対応する値}となる要素が追加される
10. 集合(set)の作成
数学における集合は,要素が並んでいる順序は区別しない.例えば,集合 と集合
と集合 は同じ集合で,
は同じ集合で, が成り立つ.
が成り立つ.
もっとはっきり言えば,集合にはある要素が入っているか否かに関心があり,同じ要素を何回書いていても,入っていることには変わりはない.例えば,集合 と集合
と集合 は同じ集合で,のように書いても,それはを表しているものと見なす.
は同じ集合で,のように書いても,それはを表しているものと見なす.
この事情は,Pythonにおける集合についても同様で,Pythonでは1つの集合の中に「同じ値」を書いても,1つだけあると見なされる.集合のこの性質は,「辞書のキー」にように「ただ1通り」でなければならないものの取り扱いに適している.
もっとはっきり言えば,集合にはある要素が入っているか否かに関心があり,同じ要素を何回書いていても,入っていることには変わりはない.例えば,集合
この事情は,Pythonにおける集合についても同様で,Pythonでは1つの集合の中に「同じ値」を書いても,1つだけあると見なされる.集合のこの性質は,「辞書のキー」にように「ただ1通り」でなければならないものの取り扱いに適している.
(1) {値1, 値2, ... }による集合の作成
【例 10.1】
>>> s1 = {1, 3.14, 'a', 'boy'}
>>> s1
→ {'boy', 1, 'a', 3.14}
• 整数,浮動小数点数,文字列など,型が異なるものも1つの集合の要素になることができる.
• 集合の要素には「並び方の順序というものが決まっていない」ので,入力した順に表示されるとは限らない.
>>> s1 = {1, 3.14, 'a', 'boy'}
>>> s1
→ {'boy', 1, 'a', 3.14}
• 整数,浮動小数点数,文字列など,型が異なるものも1つの集合の要素になることができる.
• 集合の要素には「並び方の順序というものが決まっていない」ので,入力した順に表示されるとは限らない.
>>> s2 = {'a','b','a','c'}
>>> s2
→ {'c', 'b', 'a'}
• 集合には同じ要素は重複して存在できないから,重複して入力した要素は取り除かれる.
>>> s2
→ {'c', 'b', 'a'}
• 集合には同じ要素は重複して存在できないから,重複して入力した要素は取り除かれる.
(2) set()関数による集合の作成
【例 10.2】
>>> str1 = 'ABCDE'
>>> s1 = set(str1)
>>> s1
→ {'C', 'E', 'A', 'D', 'B'}
• set(文字列)とすると,1文字ずつを要素とする集合になる.
>>> str1 = 'ABCDE'
>>> s1 = set(str1)
>>> s1
→ {'C', 'E', 'A', 'D', 'B'}
• set(文字列)とすると,1文字ずつを要素とする集合になる.
>>> L1 =['I','am','a','boy.']
>>> s2 = set(L1)
>>> s2
→ {'boy.', 'am', 'I', 'a'}
• set(リスト)とすると,リストの要素から成る集合ができる.この例では,リストの要素は単語だったから,単語を要素とする集合ができる.
>>> s2 = set(L1)
>>> s2
→ {'boy.', 'am', 'I', 'a'}
• set(リスト)とすると,リストの要素から成る集合ができる.この例では,リストの要素は単語だったから,単語を要素とする集合ができる.
>>> tp1 = ('When','What','Who')
>>> s3 = set(tp1)
>>> s3
→ {'What', 'When', 'Who'}
• set(タプル)とすると,タプルの要素から成る集合ができる.
>>> s3 = set(tp1)
>>> s3
→ {'What', 'When', 'Who'}
• set(タプル)とすると,タプルの要素から成る集合ができる.
>>> d1 = {'a':'arm','b':'big','c':'camera'}
>>> s4 = set(d1)
>>> s4
→ {'c', 'b', 'a'}
• set(辞書)とすると,「辞書のキーだけ」を要素とする集合ができる.他の型と違うので要注意
>>> s5 = set(d1.values())
>>> s5
→ {'arm', 'big', 'camera'}
• 「辞書の値」を要素とする集合を作るには,set(辞書.values())とすればよい.
>>> s4 = set(d1)
>>> s4
→ {'c', 'b', 'a'}
• set(辞書)とすると,「辞書のキーだけ」を要素とする集合ができる.他の型と違うので要注意
>>> s5 = set(d1.values())
>>> s5
→ {'arm', 'big', 'camera'}
• 「辞書の値」を要素とする集合を作るには,set(辞書.values())とすればよい.
11. 集合の要素の追加,削除
(1) 集合.add(x)による要素xの追加
【例 11.1】
>>> s1 = {'a','b','c'}
>>> s1.add('d')
>>> s1
→ {'c', 'b', 'a', 'd'}
>>> s1 = {'a','b','c'}
>>> s1.add('d')
>>> s1
→ {'c', 'b', 'a', 'd'}
(2) 集合.remove(x)による要素xの削除
【例 11.2】
>>> s1 = {'a','b','c'}
>>> s1.remove('b')
>>> s1
→ {'c', 'a'}
>>> s1 = {'a','b','c'}
>>> s1.remove('b')
>>> s1
→ {'c', 'a'}
>>> s2 = {'a','b','c'}
>>> s2.remove('d')
→ エラー (remove(x)で要素でないものxを取り除こうとするとエラーになる)
>>> s2.remove('d')
→ エラー (remove(x)で要素でないものxを取り除こうとするとエラーになる)
(3) 集合.discard(x)により要素xがあれば削除する
【例 11.3】
>>> s1 = {'a','b','c'}
>>> s1.discard('b')
>>> s1
→ {'c', 'a'}
>>> s1 = {'a','b','c'}
>>> s1.discard('b')
>>> s1
→ {'c', 'a'}
>>> s2 = {'a','b','c'}
>>> s2.discard('d')
>>> s1
→ {'c', 'b', 'a'}
(discard(x)はxが要素であれば取り除くが,要素でなければ何もしない.だから,xが要素でなくてもエラーにならない)
>>> s2.discard('d')
>>> s1
→ {'c', 'b', 'a'}
(discard(x)はxが要素であれば取り除くが,要素でなければ何もしない.だから,xが要素でなくてもエラーにならない)
(4) 集合.pop()により集合の要素を1つ減らす
【例 11.4】
>>> s1 = {'a','b','c'}
>>> s1.pop()
→ 'b'
>>> s1
→ {'c', 'a'} (取り出す要素は決まっていない.とにかく1つ減らす)
(空集合になってからpop()を使うとエラーになる)
>>> s1 = {'a','b','c'}
>>> s1.pop()
→ 'b'
>>> s1
→ {'c', 'a'} (取り出す要素は決まっていない.とにかく1つ減らす)
(空集合になってからpop()を使うとエラーになる)
(5) 集合.clear()により集合の要素を全部削除する
【例 11.5】
>>> s1 = {'a','b','c'}
>>> s1.clear()
>>> s1
→ set()
• ブレース(波かっこ)を使った記号 { } は辞書の方を優先的に表す(空の辞書)ので,空集合を { } で表すことはできない.そこで,要素なしの集合をset()で表す.
>>> s1 = {'a','b','c'}
>>> s1.clear()
>>> s1
→ set()
• ブレース(波かっこ)を使った記号 { } は辞書の方を優先的に表す(空の辞書)ので,空集合を { } で表すことはできない.そこで,要素なしの集合をset()で表す.
12. 集合間の演算
(1) 集合1と集合2の和集合の作成
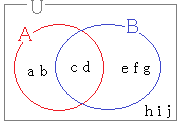 • 2つの集合
• 2つの集合すなわち,
ⅰ) ビット演算子 | で和集合を作る方法
【例 12.1.1】
>>> s1 = {'a','b'}
>>> s2 = {'c','b'}
>>> s3 = s1 | s2
>>> s3
→ {'c', 'b', 'a'}
※なお,論理演算子 or でつないでも和集合にはならない.>>> s1 = {'a','b'}
>>> s2 = {'c','b'}
>>> s3 = s1 | s2
>>> s3
→ {'c', 'b', 'a'}
3個以上の集合についても,ビット演算子 | で和集合を作ることができる
>>> s1 = {'a','b'}
>>> s2 = {'c','d'}
>>> s3 = {'d','e'}
>>> s1 | s2 | s3
→ {'a', 'e', 'b', 'c', 'd'}
>>> s1 = {'a','b'}
>>> s2 = {'c','d'}
>>> s3 = {'d','e'}
>>> s1 | s2 | s3
→ {'a', 'e', 'b', 'c', 'd'}
ⅱ) 集合1.union(集合2) で和集合を作る方法
【例 12.1.2】
>>> s1 = {'a','b'}
>>> s2 = {'c','b'}
>>> s3 = s1.union(s2)
>>> s3
→ {'c', 'b', 'a'} (s3 = s2.union(s1)としても同じ結果になります)
>>> s1 = {'a','b'}
>>> s2 = {'c','b'}
>>> s3 = s1.union(s2)
>>> s3
→ {'c', 'b', 'a'} (s3 = s2.union(s1)としても同じ結果になります)
3個以上の集合についても,union(集合)で和集合を作ることができる
>>> s1 = {'a','b'}
>>> s2 = {'c','d'}
>>> s3 = {'d','e'}
>>> s1.union(s2).union(s3)
→ {'a', 'e', 'b', 'c', 'd'}
>>> s1 = {'a','b'}
>>> s2 = {'c','d'}
>>> s3 = {'d','e'}
>>> s1.union(s2).union(s3)
→ {'a', 'e', 'b', 'c', 'd'}
(2) 集合1と集合2の積集合の作成
• 2つの集合すなわち,
ⅰ) ビット演算子 & で積集合を作る方法
【例 12.2.1】
>>> s1 = {'a','b'}
>>> s2 = {'c','b'}
>>> s3 = s1 & s2
>>> s3
→ {'b'}
※なお,論理演算子 and でつないでも積集合にはならない.>>> s1 = {'a','b'}
>>> s2 = {'c','b'}
>>> s3 = s1 & s2
>>> s3
→ {'b'}
>>> s1 = {'a','b'}
>>> s2 = {'c','d'}
>>> s3 = s1 & s2
>>> s3
→ set()
(積集合[共通部分]がないとき,すなわち空集合になるとき,空集合は{ }とは書けない(これは空の辞書の記号になる)から,set()と表示される)
• 3個以上の集合s1, s2, s3, ...についてもs1 & s2 & s3 & … とすることができる.
>>> s2 = {'c','d'}
>>> s3 = s1 & s2
>>> s3
→ set()
(積集合[共通部分]がないとき,すなわち空集合になるとき,空集合は{ }とは書けない(これは空の辞書の記号になる)から,set()と表示される)
ⅱ) 集合1.intersection(集合2)で積集合を作る方法
【例 12.2.2】
>>> s1 = {'a','b'}
>>> s2 = {'c','b'}
>>> s3 = s1.intersection(s2)
>>> s3
→ {'b'}
• 3個以上の集合s1, s2, s3, ...についてもs1.intersection(s2).intersection(s3)… とすることができる.
>>> s1 = {'a','b'}
>>> s2 = {'c','b'}
>>> s3 = s1.intersection(s2)
>>> s3
→ {'b'}
• 3個以上の集合s1, s2, s3, ...についてもs1.intersection(s2).intersection(s3)… とすることができる.
(3) 集合1と集合2の差集合の作成
• 2つの集合すなわち,
差の順序を入れ換えると,
ⅰ) 集合1−集合2 で差集合を作る方法
【例 12.3.1】
>>> s1 = {'a','b'}
>>> s2 = {'c','b'}
>>> s3 = s1−s2
>>> s3
→ {'a'}
>>> s4 = s2−s1
>>> s4
→ {'c'}
>>> s1 = {'a','b'}
>>> s2 = {'c','b'}
>>> s3 = s1−s2
>>> s3
→ {'a'}
>>> s4 = s2−s1
>>> s4
→ {'c'}
• 3個以上の集合s1, s2, s3, ...についてもs1−s2−s3−… とすることができる.
>>> s1 = {1,2,3,4}
>>> s2 = {2,3,5,6}
>>> s3 = {3,4,6,7}
>>> s1−s2−s3
→ {1}
>>> s1 = {1,2,3,4}
>>> s2 = {2,3,5,6}
>>> s3 = {3,4,6,7}
>>> s1−s2−s3
→ {1}
ⅱ) 集合1.differnce(集合2)によっても差集合を作れる(略)
(4) 集合1と集合2の排他的論理和(XOR)の作成
• 2つの集合すなわち,
ⅰ) カレット演算子(^)を使って集合1 ^ 集合2 で排他的論理和(XOR)を作る方法
【例 12.4.1】
>>> s1 = {'a','b'}
>>> s2 = {'c','b'}
>>> s3 = s1 ^ s2
>>> s3
→ {'a', 'c'} (s1,s2の一方にだけ属する要素が示される)
>>> A = {1,2,3,4}
>>> B = {2,3,5,6}
>>> C = {3,4,6,7}
>>> A ^ B ^ C
→ {1, 3, 5, 7}
(Aだけ→1,Bだけ→5,Cだけ→7,これ以外に3重の箇所→3も入る.)
(まずA^Bに2,3が入らないから,3はA^BとCの一方にだけ入る)
>>> A = {1,5,6,7,11,12,13,15}
>>> B = {2,5,8,9,11,12,14,15}
>>> C = {3,6,8,10,11,13,14,15}
>>> D = {4,7,9,10,12,13,14,15}
>>> A ^ B ^ C ^ D
→ {1, 2, 3, 4, 11, 12, 13, 14}
(結果はつねに市松模様[チェックの図柄]になり,A,B,Cの中をDが通り過ぎていくような動画において,排他的論理和で図形を描くと「どの境界線も生きる」…1重,3重のように奇数回重なるところが残る)
>>> s1 = {'a','b'}
>>> s2 = {'c','b'}
>>> s3 = s1 ^ s2
>>> s3
→ {'a', 'c'} (s1,s2の一方にだけ属する要素が示される)
途中経過:A^Bの図
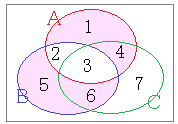
3個の集合についても排他的論理和を求めることができるが,結果に注意
>>> A = {1,2,3,4}
>>> B = {2,3,5,6}
>>> C = {3,4,6,7}
>>> A ^ B ^ C
→ {1, 3, 5, 7}
(Aだけ→1,Bだけ→5,Cだけ→7,これ以外に3重の箇所→3も入る.)
(まずA^Bに2,3が入らないから,3はA^BとCの一方にだけ入る)
結果:A^B^C^Dの図
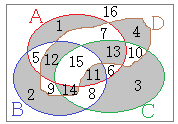
4個の集合についても排他的論理和を求めることができる.
>>> A = {1,5,6,7,11,12,13,15}
>>> B = {2,5,8,9,11,12,14,15}
>>> C = {3,6,8,10,11,13,14,15}
>>> D = {4,7,9,10,12,13,14,15}
>>> A ^ B ^ C ^ D
→ {1, 2, 3, 4, 11, 12, 13, 14}
(結果はつねに市松模様[チェックの図柄]になり,A,B,Cの中をDが通り過ぎていくような動画において,排他的論理和で図形を描くと「どの境界線も生きる」…1重,3重のように奇数回重なるところが残る)
ⅱ) 集合1.symmetric_difference(集合2)によっても排他的論理和(XOR)の集合を作れる(略)
13. 集合間の包含関係
(1) 集合1⊂集合2の判別
(備考) 高校以上の数学における部分集合,真部分集合の記号
たぶん,昔(昭和40年代頃までか?)は,集合 が集合
が集合 の真部分集合(等しい場合はない)であることを
の真部分集合(等しい場合はない)であることを で表し,部分集合(等しい場合もよい)であることを
で表し,部分集合(等しい場合もよい)であることを で表していた.
で表していた.
すなわち,不等号の使い方とよく似た形で
 が成り立つとき,と書き
が成り立つとき,と書き
かつ が成り立つとき,と書いていた.
が成り立つとき,と書いていた.
しかし,今日では,国際的な表記と合わせたのかどうか定かではないが,記号の使い方が次のようになっているので,注意を要する.
が成り立つとき,と書き
かつが成り立つとき,
さらに,話がややこしくなるが,Pythonにおいて集合の包含関係の判別は,不等号を利用して行われるので「昔の集合記号の使い方」とよく似ている.
たぶん,昔(昭和40年代頃までか?)は,集合
すなわち,不等号の使い方とよく似た形で
しかし,今日では,国際的な表記と合わせたのかどうか定かではないが,記号の使い方が次のようになっているので,注意を要する.
さらに,話がややこしくなるが,Pythonにおいて集合の包含関係の判別は,不等号を利用して行われるので「昔の集合記号の使い方」とよく似ている.
ⅰ) 不等号の演算子によって判別する方法
【例 13.1.1】
>>> s1 = {'a','b','c'}
>>> s2 = {'a','c'}
>>> s2 <= s1
→ True
(なお,<=の記号は,間にスペースを入れて< =と書くとエラーになる.また,=<と書くのもエラーになる.)
→ True
(s2はs2自身のsupersetだから,Trueになる)
>>> s1 = {'a','b','c'}
>>> s2 = {'a','c'}
>>> s2 <= s1
→ True
(なお,<=の記号は,間にスペースを入れて< =と書くとエラーになる.また,=<と書くのもエラーになる.)
>>> s1 <= s1
→ True
(集合が等しい場合も,部分集合になる)
→ True
(集合が等しい場合も,部分集合になる)
>>> s2 < s1
→ True
(真部分集合であるか否かの判定は,等号なし不等号で行う)
→ True
(真部分集合であるか否かの判定は,等号なし不等号で行う)
>>> s1 >= s2
→ True
( のとき,すなわちBがAの部分集合subsetであるとき,AはBの拡大集合[または上位集合]supersetと呼ぶことがある.これは,不等号の向きを逆にすれば調べられる)
のとき,すなわちBがAの部分集合subsetであるとき,AはBの拡大集合[または上位集合]supersetと呼ぶことがある.これは,不等号の向きを逆にすれば調べられる)
>>> s2 >= s2→ True
(
→ True
(s2はs2自身のsupersetだから,Trueになる)
>>> s2 > s1
→ False
(s2はs1の真上位集合[真拡大集合]でないから,Falseになる)
→ False
(s2はs1の真上位集合[真拡大集合]でないから,Falseになる)
ⅱ) 集合1.issubset(集合2),集合1.issuperset(集合2)によって判別する方法
部分集合,拡大集合の判別は,集合1.issubset(集合2),集合1.issuperset(集合2)によっても行えるが,このメソッドでは真部分集合,真拡大集合を判別するには,論理演算子 and と組合わせて使う必要がある.
【例 13.1.2】
>>> s1 = {'a','b','c'}
>>> s2 = {'a','c'}
>>> s2.issubset(s1)
→ True
>>> s1 = {'a','b','c'}
>>> s2 = {'a','c'}
>>> s2.issubset(s1)
→ True
>>> s1.issuperset(s1)
→ True
(集合が等しい場合も,拡大集合,部分集合になる)
→ True
(集合が等しい場合も,拡大集合,部分集合になる)
>>> s2.issubset(s1) and (s1 != s2)
→ True
(真部分集合であるか否かの判定は,等しくないことと組み合わせる)
→ True
(真部分集合であるか否かの判定は,等しくないことと組み合わせる)
(2) 集合1.isdisjoint(集合2)による共通部分(積集合)の有無の判別
【例 13.2.1】
>>> s1 = {'a','b','c'}
>>> s2 = {'a','c'}
>>> s3 = {'d','e'}
>>> s1.isdisjoint(s2)
→ False
(共通部分がなければTrue,共通部分があればFalseを返す)
>>> s1 = {'a','b','c'}
>>> s2 = {'a','c'}
>>> s3 = {'d','e'}
>>> s1.isdisjoint(s2)
→ False
(共通部分がなければTrue,共通部分があればFalseを返す)
>>> s2.isdisjoint(s1)
→ False
(立場を入れ換えても結果は同じ)
→ False
(立場を入れ換えても結果は同じ)
>>> s1.isdisjoint(s3)
→ True
(s1とs3の共通部分が空集合になるかどうかは,(s1 & s3) == set()でも調べられる.(s1 & s3) == {}では空の辞書と比較するのでFalseになる)
→ True
(s1とs3の共通部分が空集合になるかどうかは,(s1 & s3) == set()でも調べられる.(s1 & s3) == {}では空の辞書と比較するのでFalseになる)
14. 集合の要素の情報
(1) len(集合)により集合の要素数を調べる
【例 14.1】
>>> s1 = {'a','b','c'}
>>> len(s1)
→ 3
• なお,集合の要素には「順序というものは考えない」から,s1[1]のようなオフセットによる要素の取り出しは不可能
>>> s1 = {'a','b','c'}
>>> len(s1)
→ 3
• なお,集合の要素には「順序というものは考えない」から,s1[1]のようなオフセットによる要素の取り出しは不可能
(2) x in 集合によりxが集合の要素であるか否かを調べる
【例 14.2】
>>> s1 = {'a','b','c'}
>>> 'b' in s1
→ True
>>> s1 = {'a','b','c'}
>>> 'b' in s1
→ True
(3) x not in 集合によりxが集合の要素でなければTrue,要素であればFlaseを返す
【例 14.3】
>>> s1 = {'a','b','c'}
>>> 'd' not in s1
→ True
>>> s1 = {'a','b','c'}
>>> 'd' not in s1
→ True
15. 集合を使ったイテレーション
【例 15】
>>> s1 = {'a','b','c'}
>>> for xx in s1:
>>> print(xx, end=' ')
→ b a c (順不同に全部の要素をたどる)
>>> s1 = {'a','b','c'}
>>> for xx in s1:
>>> print(xx, end=' ')
→ b a c (順不同に全部の要素をたどる)